
Python 陷阱|第1章:字符编码问题

Synopsis: (Decode)将二进制字节序列解码成 Unicode code points,(Encode)将 Unicode code points 编码成二进制字节序列
建议先阅读 Unicode 字符集与 UTF-8 编码方案
1. Python 2.x
1.1 要点
Python 2 的默认编码为 ASCII:
Python 2 中的 str 类型表示字节序列,unicode 类型表示 Unicode 字符序列(Unicode characters,Unicode code points)
内建函数:
ord(): 返回单个字符的整数表示,比如ord('A')输出65、ord(u'汉')输出27721chr(): 返回 0 - 256 整数(超过范围则报错)所对应的单个字符,比如chr(65)输出'A'unichr(): 返回 0 - 0x10FFFF 整数(超过范围则报错)所对应的单个 Unicode character,比如unichr(65)输出u'A'、unichr(0x6C49)输出u'\u6c49'str(): 返回字符串的 binary bytes(不同的操作系统输出不同),比如str('你好')在 cmd 终端中输出'\xc4\xe3\xba\xc3',在 Xshell 终端中输出'\xe4\xbd\xa0\xe5\xa5\xbd'unicode(): 根据 encoding 返回字符串的 Unicode characters,比如unicode('你好', encoding='utf-8')输出u'\u4f60\u597d'
1.2 最佳实践
建议用 PyCharm 等编辑器写 Python 2 源代码时,要选择以 UTF-8 编码格式保存,并且需要在源代码的头部添加一行(-*- 纯粹是为了格式好看而已):
另外,字符串建议全部使用 unicode 类型,比如:
# -*- coding: utf-8 -*- u = u'你好' # u = unicode('你好', encoding='utf-8') # u = u'\u4f60\u597d' # '♥'和'𪸿'这两个字符用 GBK 无法编码,所以后续打印输出时要主动调用 print u.encode('utf-8') # u = u'\u2665' # 对应 16 bits 的 Unicode code point # u = u'\U0002AE3F' # 对应 32 bits 的 Unicode code point print repr(u) print u
Python 2 的变量名不支持 Unicode 字符
1.3 字符编码实验
(1) 终端设置 str object
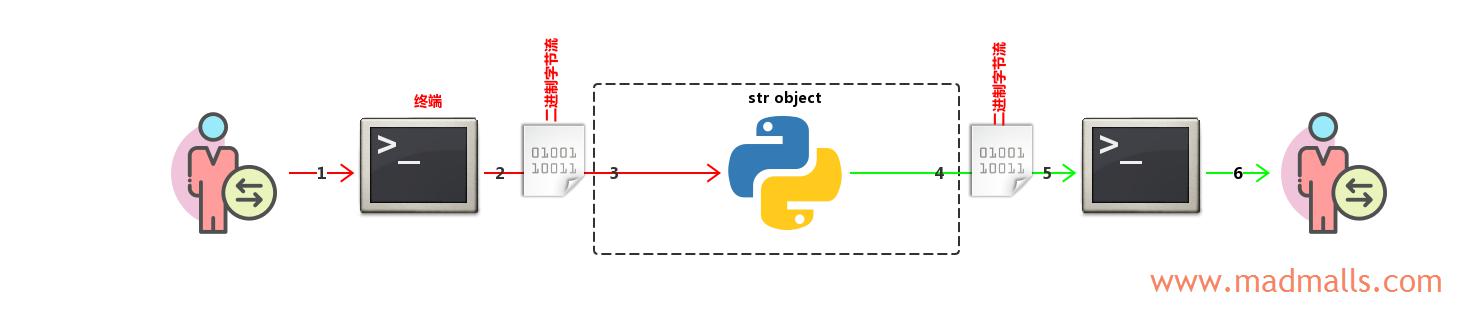
[root@CentOS ~]# python Python 2.7.5 (default, Nov 6 2016, 00:28:07) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.stdin.encoding 'UTF-8' >>> sys.stdout.encoding 'UTF-8' >>> s = '你好' >>> type(s) <type 'str'> >>> print repr(s) '\xe4\xbd\xa0\xe5\xa5\xbd' >>> print s 你好
- 用户在终端(cmd 或 Xshell)中输入文本字符,比如
'你好'。注意: 终端的编码需要设置与操作系统的一致,否则你无法正常输入字符。比如 Linux 系统默认编码为UTF-8,如果你将 Xshell 的编码设置为GBK的话,没办法正常输入汉字 - 终端会根据它自己的
编码方案(encoding)将字符编码(Encode)成二进制字节流,Windows 简体中文系统的 cmd 终端的编码为GBK(cp936),那么'你好'被转换为'\xc4\xe3\xba\xc3'; Linux 系统默认编码为UTF-8,并且我将 Xshell 的编码也设置为UTF-8,那么'你好'被转换为'\xe4\xbd\xa0\xe5\xa5\xbd' - Python 解释器接收终端发送的二进制字节流
- Python 程序内部进行一系列拼接、替换、截取等处理后,由于应用程序的输出永远是二进制字节流,而
str类型对象本来就是二进制字节流,直接输出给终端即可。所以,Windows 中输出'\xc4\xe3\xba\xc3',Linux 中输出'\xe4\xbd\xa0\xe5\xa5\xbd' - 终端接收 Python 程序发送的二进制字节流
- 终端根据它自己的编码将二进制字节流
解码(Decode)成字符,显示给用户看,最终都能正常显示字符你好
不会出现乱码,除非你在第 6 步的时候将 Xshell 的编码改成 GBK,就会出现乱码
(2) 终端设置 unicode object
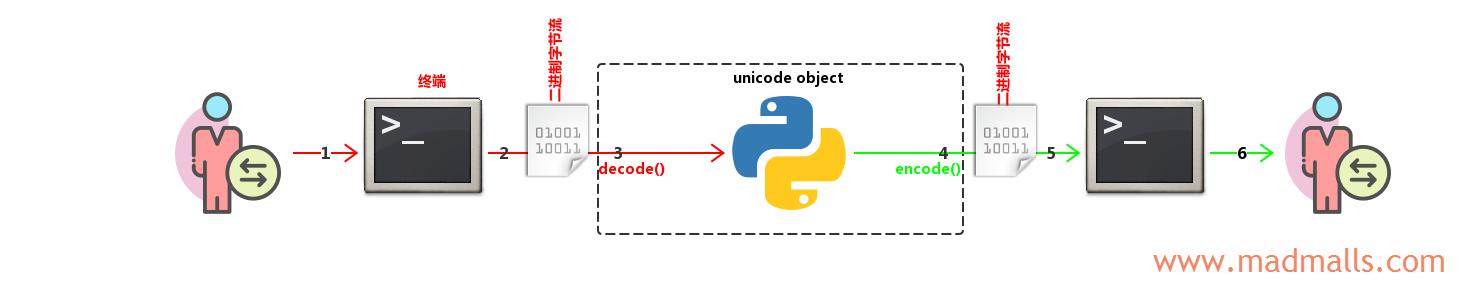
[root@CentOS ~]# python Python 2.7.5 (default, Nov 6 2016, 00:28:07) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.stdin.encoding 'UTF-8' >>> sys.stdout.encoding 'UTF-8' >>> u = u'你好' >>> type(u) <type 'unicode'> >>> print repr(u) u'\u4f60\u597d' >>> print u 你好
- 用户在终端(cmd 或 Xshell)中输入文本字符,比如
'你好'。注意: 终端的编码需要设置与操作系统的一致,否则你无法正常输入字符。比如 Linux 系统默认编码为UTF-8,如果你将 Xshell 的编码设置为GBK的话,没办法正常输入汉字 - 终端会根据它自己的
编码方案(encoding)将字符编码(Encode)成二进制字节流,Windows 简体中文系统的 cmd 终端的编码为GBK(cp936),那么'你好'被转换为'\xc4\xe3\xba\xc3'; Linux 系统默认编码为UTF-8,并且我将 Xshell 的编码也设置为UTF-8,那么'你好'被转换为'\xe4\xbd\xa0\xe5\xa5\xbd' - Python 解释器接收终端发送的二进制字节流,并根据
sys.stdin.encoding的编码(Windows 中为 GBK,Linux 中为 UTF-8)将二进制字节流解码(Decode)成unicode对象(表示 Unicode characters),所以不管什么操作系统,最终都能转换成u'\u4f60\u597d' - Python 程序内部进行一系列拼接、替换、截取等处理后,由于应用程序的输出永远是二进制字节流,所以需要调用
encode('xxx')或者自动根据sys.stdout.encoding的编码(Windows 中为 GBK,Linux 中为 UTF-8)将unicode对象编码(Encode)成二进制字节流,输出给终端。所以,Windows 中输出'\xc4\xe3\xba\xc3',Linux 中输出'\xe4\xbd\xa0\xe5\xa5\xbd' - 终端接收 Python 程序发送的二进制字节流
- 终端根据它自己的编码将二进制字节流
解码(Decode)成字符,显示给用户看,最终都能正常显示字符你好
由于终端的编码、sys.stdin.encoding、sys.stdout.encoding 这三者一般都是与操作系统的默认编码一致,所以不会出现乱码
除非你在第 6 步的时候将 Xshell 的编码改成 GBK,就会出现乱码
(3) 源代码文件中只有 str object
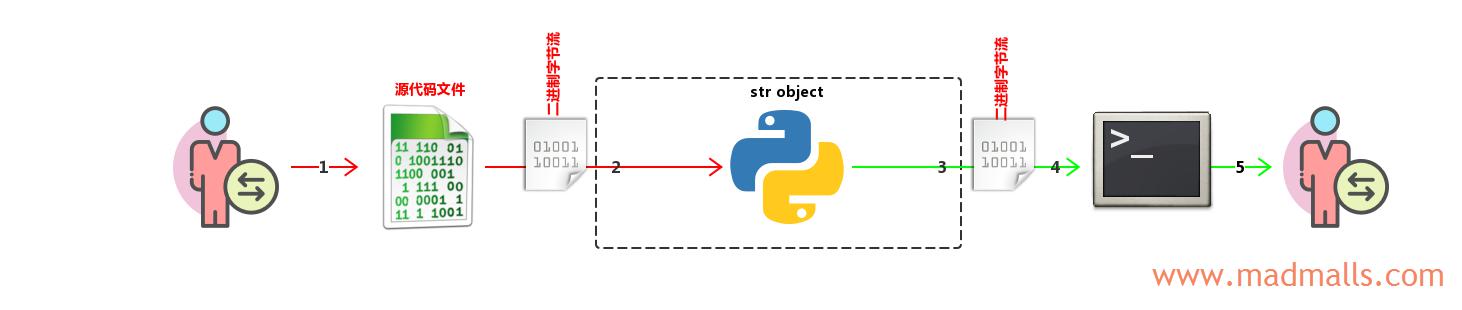
源代码如下(按 UTF-8 格式保存):
- 用户在 PyCharm 等编辑器中输入源代码字符,由编辑器根据它的编码转换成二进制字节流,并保存到磁盘上的文件中
- Python 解释器读取源文件,接收二进制字节流。在语法校验期间(compilation),如果源代码文件的头部指明了源代码的编码,则使用此编码来进行词法分析;如果源代码文件的头部没有指明源代码的编码,那么 Python 2 解释器会使用它的默认编码
ASCII(由sys.getdefaultencoding()指定)来对源代码进行词法分析。如果选择的编码(codec)无法解析源代码中的某些字节的话(比如,用 ASCII 去解析非 ASCII 字符的字节),就会报错SyntaxError: 'xxx' codec can't decode bytes。如果语法校验通过,则str类型对象 s 的值为'\xe4\xbd\xa0\xe5\xa5\xbd' - Python 程序内部进行一系列拼接、替换、截取等处理后,由于应用程序的输出永远是二进制字节流,而
str类型对象本来就是二进制字节流,直接将'\xe4\xbd\xa0\xe5\xa5\xbd'输出给终端即可 - 终端接收 Python 程序发送的二进制字节流
- 终端根据它自己的编码将二进制字节流
解码(Decode)成字符,显示给用户看。由于终端的编码各不相同,所以 Xshell 用UTF-8能正常解码出字符你好,而 cmd 用GBK解码时显示乱码浣犲ソ,因为浣的 GBK 编码为\xe4\xbd、犲的 GBK 编码为\xa0\xe5、ソ的 GBK 编码为\xa5\xbd
在 Linux 中运行时正常:
在 Windows 中运行时返回乱码:
同样的原理,如果源代码保存时选择 GBK,则 cmd 中显示正常,而 Xshell 中显示乱码(当然,此时你把 Xshell 的编码改成 GBK 的话也可以显示正常)
(4) 源代码文件中只有 unicode object
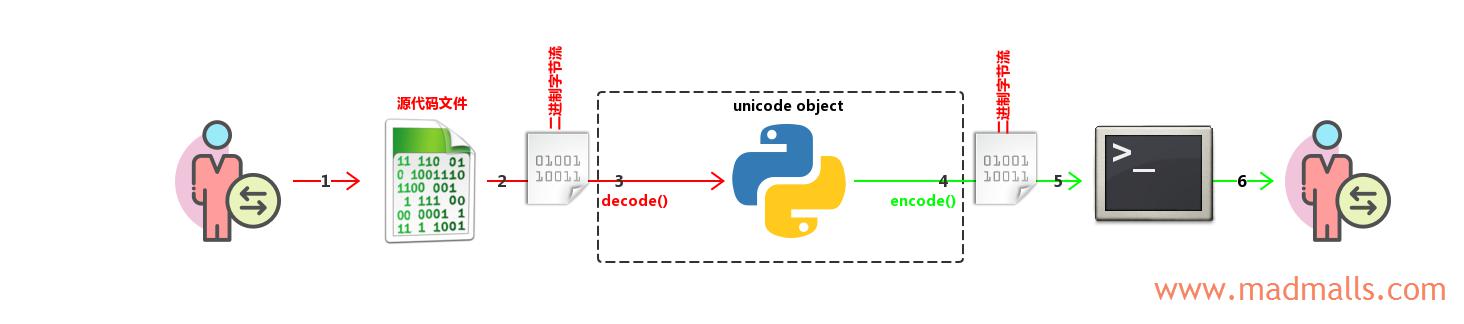
源代码如下(按 UTF-8 格式保存):
# -*- coding: utf-8 -*- u = u'你好' print repr(u) print u # 建议 Linux 平台用 u.encode('utf-8'),Windows 平台用 u.encode('gbk')
- 用户在 PyCharm 等编辑器中输入源代码字符,由编辑器根据它的编码转换成二进制字节流,并保存到磁盘上的文件中
- Python 解释器读取源文件,接收二进制字节流。在语法校验期间(compilation),如果源代码文件的头部指明了源代码的编码,则使用此编码来进行词法分析;如果源代码文件的头部没有指明源代码的编码,那么 Python 2 解释器会使用它的默认编码
ASCII(由sys.getdefaultencoding()指定)来对源代码进行词法分析。如果选择的编码(codec)无法解析源代码中的某些字节的话(比如,用 ASCII 去解析非 ASCII 字符的字节),就会报错SyntaxError: 'xxx' codec can't decode bytes。如果语法校验通过,则 Python 解释器接收'你好'所对应的二进制字节流'\xe4\xbd\xa0\xe5\xa5\xbd' - Python 解释器根据源代码文件的头部指定的编码将二进制字节流
'\xe4\xbd\xa0\xe5\xa5\xbd'解码成u'\u4f60\u597d',然后赋值给unicode类型对象 u - Python 程序内部进行一系列拼接、替换、截取等处理后,由于应用程序的输出永远是二进制字节流,所以需要调用
encode('xxx')或者自动根据sys.stdout.encoding的编码(Windows 中为 GBK,Linux 中为 UTF-8)将unicode对象编码(Encode)成二进制字节流,输出给终端。所以,Windows 中输出'\xc4\xe3\xba\xc3',Linux 中输出'\xe4\xbd\xa0\xe5\xa5\xbd' - 终端接收 Python 程序发送的二进制字节流
- 终端根据它自己的编码将二进制字节流
解码(Decode)成字符,显示给用户看,最终都能正常显示字符你好
由于 sys.stdout.encoding 和终端的编码一般都是与操作系统的默认编码一致,所以不会出现乱码
1.4 常见陷阱
(1) SyntaxError: Non-ASCII character
源代码如下(按 UTF-8 格式保存):
运行时报如下异常:
[root@CentOS ~]# python utf8.py File "utf8.py", line 1 SyntaxError: Non-ASCII character '\xe4' in file utf8.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
原因是源代码文件开头没有指定编码方式时,Python 2 解释器默认使用它的默认编码 ASCII 去对源代码进行词法分析,如果源代码中包含非 ASCII 字符时(包括注释信息),就会报以上异常
如果在源代码文件开头指定了错误的编码方式时,比如:
运行时输出的字符是乱码(原理参考章节 1.3 - 4):
[root@CentOS ~]# python utf8.py u'\u6d63\u72b2\u30bd' # 将 '\xe4\xbd\xa0\xe5\xa5\xbd' 用 GBK 解码后所得 浣犲ソ # 输出时,将 u'\u6d63\u72b2\u30bd' 用 UTF-8 编码后得到字节序列 '\xe6\xb5\xa3\xe7\x8a\xb2\xe3\x82\xbd',再通过 Xshell 用 UTF-8 解码显示出字符
如果你错误地指定为韩语字符集:
连词法分析都无法通过:
[root@CentOS ~]# python utf8.py File "utf8.py", line 3 SyntaxError: 'euc_kr' codec can't decode bytes in position 8-9: illegal multibyte sequence
(2) UnicodeDecodeError
UnicodeDecodeError 异常是因为将字节序列 str 类型解码成 unicode 类型时,指定了错误的编码系统(encoding)时会出现:
>>> s = '你好' >>> s # 假设在 Linux 系统中,默认 Xshell 使用 UTF-8,所以字符 '你好' 按 UTF-8 编码后的二进制序列是 '\xe4\xbd\xa0\xe5\xa5\xbd' '\xe4\xbd\xa0\xe5\xa5\xbd' >>> type(s) <type 'str'> >>> s.decode() # 不指定编码时,默认使用 ASCII Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) >>> s.decode('euc-kr') # 指定错误的编码时,无法解码 Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'euc_kr' codec can't decode bytes in position 2-3: illegal multibyte sequence >>> s.decode('gbk') # GBK 是错误的编码,能解码,但生成的 Unicode 不对 u'\u6d63\u72b2\u30bd' >>> s.decode('utf-8') # 正确应该用 UTF-8 解码 u'\u4f60\u597d'
出现最多的情况是,用户不清楚当前对象的类型,比如对 str 类型对象调用 encode() 方法。此时,Python 2 解释器会自动用 ASCII 想将 str 对象解码成 Unicode,此过程就会报错:
>>> s = '你好' >>> s '\xe4\xbd\xa0\xe5\xa5\xbd' >>> type(s) <type 'str'> >>> s.encode('utf-8') # 内部实际上是 s.decode().encode('utf-8') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
另外一种情况是,直接对 str 类型对象和 unicode 类型对象进行拼接。此时,Python 2 解释器会自动用 ASCII 想将 str 对象解码成 Unicode 后再拼接,此过程就会报错:
>>> s = '你好' >>> u = u'世界' >>> s + u Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
(3) UnicodeEncodeError
UnicodeEncodeError 异常是因为将 unicode 类型编码成二进制字节序列时,指定了错误的编码系统(encoding)时会出现:
>>> u = u'你好' >>> u u'\u4f60\u597d' >>> type(u) <type 'unicode'> >>> u.encode() # 不指定编码时,默认使用 ASCII Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) >>> u.encode('euc-kr') # 无法按 euc-kr 编码,是因为 euc-kr 跟 ASCII 字符集一样没有 '你' 和 '好' 这两个字符 Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'euc_kr' codec can't encode character u'\u4f60' in position 0: illegal multibyte sequence >>> u.encode('gbk') # 能够按 GBK 编码是因为 GBK 字符集中有 '你' 和 '好' 这两个字符 '\xc4\xe3\xba\xc3' >>> u.encode('utf-8') # 将 Unicode 按 UTF-8 编码后生成的字节序列 '\xe4\xbd\xa0\xe5\xa5\xbd'
出现最多的情况是,用户不清楚当前对象的类型,比如对 unicode 类型对象调用 decode() 方法。此时,Python 2 解释器会自动用 ASCII 想将 unicode 对象编码成字节序列,此过程就会报错:
>>> u = u'你好' >>> u u'\u4f60\u597d' >>> type(u) <type 'unicode'> >>> u.decode('utf-8') # 内部实际上是 u.encode().decode('utf-8') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/lib64/python2.7/encodings/utf_8.py", line 16, in decode return codecs.utf_8_decode(input, errors, True) UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
2. Python 3.x
2.1 要点
Python 3 的默认编码为 UTF-8:
Python 3 中的 str 类型表示 Unicode 字符序列(Unicode characters,Unicode code points),bytes 类型表示字节序列
1. str类型,Unicode字符序列 s1 = '你好' # 直接输入字符 s2 = '\u4f60\u597d' # Unicode code points s3 = '\u2665' # 对于难以用输入法打出来的字符,比如'♥'和'𪸿'可以用 Unicode code point s4 = '\U0002AE3F' # 返回对象的字符串表示 d = {'name': 'Madman', 'age': 18} str(d) # Output: "{'name': 'Madman', 'age': 18}" 2. bytes类型,字节序列 b1 = b'\xe4\xbd\xa0\xe5\xa5\xbd' b2 = bytes('你好', encoding='utf-8')
内建函数:
ord(): 返回单个字符的整数表示,比如ord('A')输出65、ord('汉')输出27721chr(): 返回 0 - 0x10FFFF 整数所对应的单个字符,比如chr(0x6c49)输出'汉'str(): 返回对象的字符串表示,详情见help(str)bytes(): 返回整数的字节序列表示,详情见help(bytes)
2.2 最佳实践
建议用 PyCharm 等编辑器写 Python 3 源代码时,要选择以 UTF-8 编码格式保存即可。Python 程序接收二进制字节序列输入后,由 bytes.decode() 自动将字节序列解码成 Unicode,Python 程序内部统一使用 Unicode,输出时由 str.encode() 自动将 Unicode 编码成字节序列
字符串默认就支持 Unicode,变量名也支持 Unicode 字符:
2.3 字符编码实验
(1) 终端输入 str object
[root@CentOS ~]# python3 Python 3.6.4 (default, May 3 2019, 16:17:04) [GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.stdin.encoding 'UTF-8' >>> sys.stdout.encoding 'UTF-8' >>> s = '你好' >>> type(s) <class 'str'> >>> print(repr(s)) '你好' >>> print(s) 你好
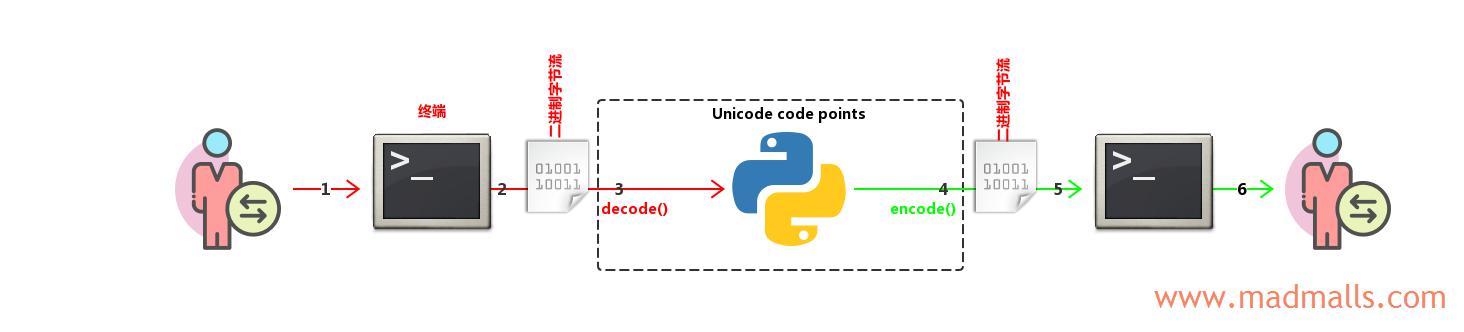
- 用户在终端(cmd 或 Xshell)中输入文本字符,比如
'你好'。注意: 终端的编码需要设置与操作系统的一致,否则你无法正常输入字符。比如 Linux 系统默认编码为UTF-8,如果你将 Xshell 的编码设置为GBK的话,没办法正常输入汉字 - 终端会根据它自己的
编码方案(encoding)将字符编码(Encode)成二进制字节流,Windows 简体中文系统的 cmd 终端的编码为GBK(cp936),那么'你好'被转换为b'\xc4\xe3\xba\xc3'; Linux 系统默认编码为UTF-8,并且我将 Xshell 的编码也设置为UTF-8,那么'你好'被转换为b'\xe4\xbd\xa0\xe5\xa5\xbd' - Python 解释器接收终端发送的二进制字节流,并根据
sys.stdin.encoding的编码(Windows 中为 GBK,Linux 中为 UTF-8)将二进制字节流解码(Decode)成str对象(表示 Unicode characters),所以不管什么操作系统,最终都能转换成'\u4f60\u597d' - Python 程序内部进行一系列拼接、替换、截取等处理后,由于应用程序的输出永远是二进制字节流,所以需要调用
encode('xxx')或者自动根据sys.stdout.encoding的编码(Windows 中为 GBK,Linux 中为 UTF-8)将str对象编码(Encode)成二进制字节流,输出给终端。所以,Windows 中输出b'\xc4\xe3\xba\xc3',Linux 中输出b'\xe4\xbd\xa0\xe5\xa5\xbd' - 终端接收 Python 程序发送的二进制字节流
- 终端根据它自己的编码将二进制字节流
解码(Decode)成字符,显示给用户看,最终都能正常显示字符你好
不会出现乱码,除非你在第 6 步的时候将 Xshell 的编码改成 GBK,就会出现乱码
(2) 源代码文件中输入 str object
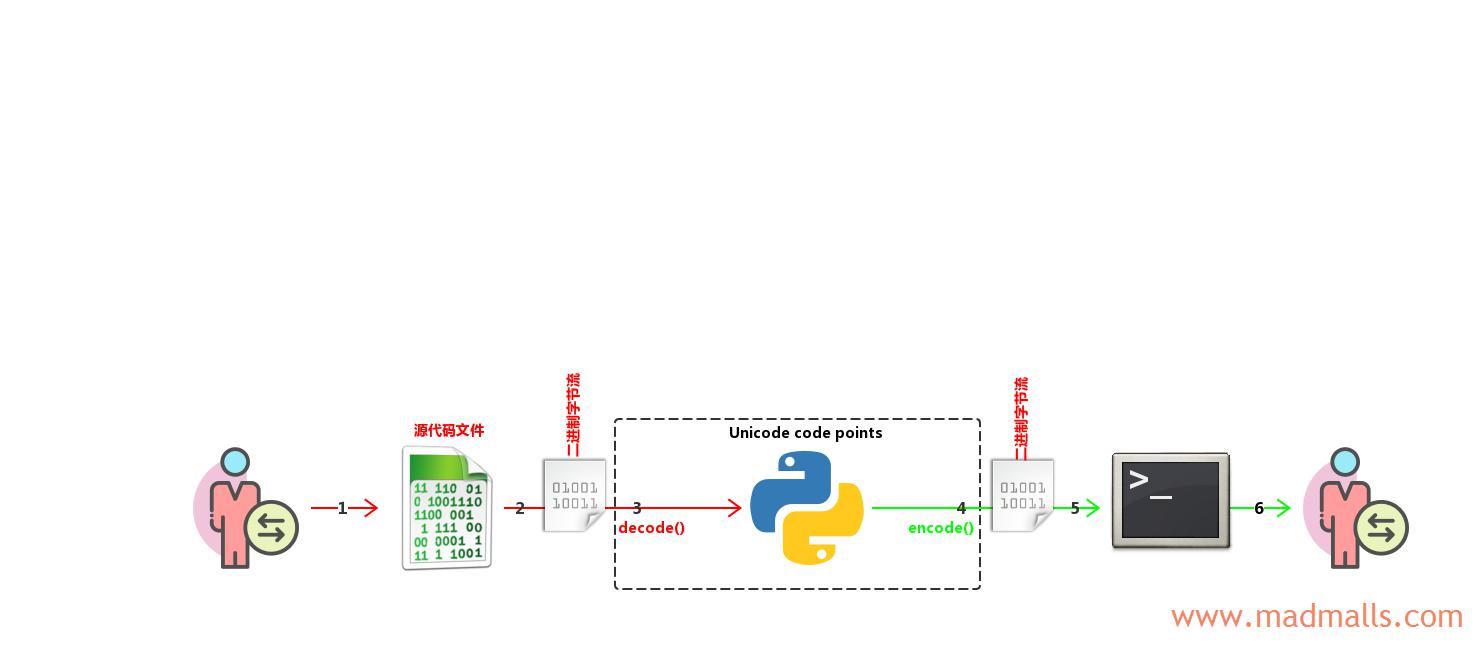
源代码如下(按 UTF-8 格式保存):
- 用户在 PyCharm 等编辑器中输入源代码字符,由编辑器根据它的编码转换成二进制字节流,并保存到磁盘上的文件中
- Python 解释器读取源文件,接收二进制字节流。在语法校验期间(compilation),如果源代码文件的头部指明了源代码的编码,则使用此编码来进行词法分析;如果源代码文件的头部没有指明源代码的编码,那么 Python 3 解释器会使用它的默认编码
UTF-8(由sys.getdefaultencoding()指定)来对源代码进行词法分析。如果选择的编码(codec)无法解析源代码中的某些字节的话(比如,源代码是 GBK 格式保存的),就会报错SyntaxError: Non-UTF-8 code starting with '\xxx'。如果语法校验通过,则 Python 解释器接收'你好'所对应的二进制字节流b'\xe4\xbd\xa0\xe5\xa5\xbd' - Python 解释器根据源代码文件的头部指定的编码或者它的默认编码
UTF-8将二进制字节流b'\xe4\xbd\xa0\xe5\xa5\xbd'解码成'\u4f60\u597d',然后赋值给str类型对象 s - Python 程序内部进行一系列拼接、替换、截取等处理后,由于应用程序的输出永远是二进制字节流,所以需要调用
encode('xxx')或者自动根据sys.stdout.encoding的编码(Windows 中为 GBK,Linux 中为 UTF-8)将str对象编码(Encode)成二进制字节流,输出给终端。所以,Windows 中输出b'\xc4\xe3\xba\xc3',Linux 中输出b'\xe4\xbd\xa0\xe5\xa5\xbd' - 终端接收 Python 程序发送的二进制字节流
- 终端根据它自己的编码将二进制字节流
解码(Decode)成字符,显示给用户看,最终都能正常显示字符你好
由于 sys.stdout.encoding 和终端的编码一般都是与操作系统的默认编码一致,所以不会出现乱码
2.4 常见陷阱
(1) SyntaxError: Non-UTF-8 code
不按最佳实践,将源代码文件保存为 GBK 编码时,但又不在文件头部指定编码方式时:
Python 3 解释器会按它的默认编码 UTF-8 去读取源代码进行词法分析,结果就会出错:
[root@CentOS ~]# python3 gbk.py File "gbk.py", line 1 SyntaxError: Non-UTF-8 code starting with '\xc4' in file gbk.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
建议你将源代码的格式转换成 UTF-8 即可,或者在文件头部添加 # -*- coding: gbk -*-
(2) UnicodeDecodeError
将字节序列 bytes 类型解码成 Unicode 字符序列 str 类型时,指定了错误的编码方式时:
>>> b = b'\xe4\xbd\xa0\xe5\xa5\xbd' # 字符 '你好' 按 UTF-8 编码后的字节序列 >>> b.decode('euc-kr') # 指定错误的编码时 Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'euc_kr' codec can't decode byte 0xa0 in position 2: illegal multibyte sequence >>> b.decode('gbk') # 乱码了,'浣' 的 GBK 编码是 '\xe4\xbd','犲' 的 GBK 编码是 '\xa0\xe5','ソ' 的 GBK 编码是 '\xa5\xbd' '浣犲ソ' >>> b.decode('utf-8') # 指定正确的编码时 '你好' >>> b.decode() # 不指定编码时,默认使用 UTF-8 '你好'
或者,当你用 mode=r 模式(文本模式)去打开一个 GBK 文件时,Python 3 解释器会自动将接收到的 GBK 编码的字节序列,按 Python 3 的默认编码 UTF-8 去解码成 Unicode,此过程就会报错:
>>> f = open('gbk.txt', 'r') >>> s = f.read() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/python-3.6/lib/python3.6/codecs.py", line 321, in decode (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
可以通过 encoding 参数明确指定编码:
>>> f = open('gbk.txt', mode='r', encoding='gbk') >>> s = f.read() >>> type(s) <class 'str'> >>> s '这是 GBK 文件'
(3) UnicodeEncodeError
UnicodeEncodeError 异常是因为将 str 类型编码成二进制字节序列时,指定了错误的编码系统(encoding)时会出现:
>>> s = '你好' >>> type(s) <class 'str'> >>> s.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) >>> s.encode('euc-kr') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'euc_kr' codec can't encode character '\u4f60' in position 0: illegal multibyte sequence >>> s.encode('gbk') b'\xc4\xe3\xba\xc3' >>> s.encode('utf-8') b'\xe4\xbd\xa0\xe5\xa5\xbd'
(4) AttributeError
Python 3 解决了 Python 2 中用户不清楚当前对象的类型乱调用 decode() 或 encode() 方法的情况,现在乱调用时,直接报 AttributeError 异常:
>>> s = '你好' >>> s.decode() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'str' object has no attribute 'decode' >>> b = b'\xe4\xbd\xa0\xe5\xa5\xbd' >>> b.encode() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'bytes' object has no attribute 'encode'
(5) TypeError
Python 3 中不能混用 str 和 bytes 类型:











0 条评论
评论者的用户名
评论时间暂时还没有评论.