
Python 3 爬虫|第2章:Python 并发编程

Synopsis: 本文是整个爬虫系列的理论基础,试想一下,如果你的爬虫只能一次下载一张图片,那要爬完整个图片网站的时间会让人抓狂,所以我们需要让程序能够并发,同时请求多张图片资源,因为网络传输时间对于 CPU 来说太漫长了,并发的好处是可以合理的解决 CPU 和网络 I/O 之间的速度鸿沟
代码已上传到 https://github.com/wangy8961/python3-concurrency ,欢迎 star
1. 并发编程
1.1 为什么需要并发
| device | CPU cycles | Proportional "human" scale |
|---|---|---|
| L1 cache | 3 | 3 seconds |
| L2 cache | 14 | 14 seconds |
| RAM | 250 | 250 seconds |
| disk | 41,000,000 | 1.3 years |
| network | 240,000,000 | 7.6 years |
假设 CPU 读取 L1 缓存要用 3 秒,那么读取网络 I/O 要用 7.6 年!CPU 的速度远快于磁盘 I/O 或网络 I/O,如果使用 同步阻塞 的方式去请求 1000 张图片,在只有一个进程的情况下,一旦遇到 I/O 操作(比如,请求第 1 张图片数据),当前进程会被挂起,直到 I/O 操作完成,才能继续请求第 2 张图片
1.2 并发与并行的区别
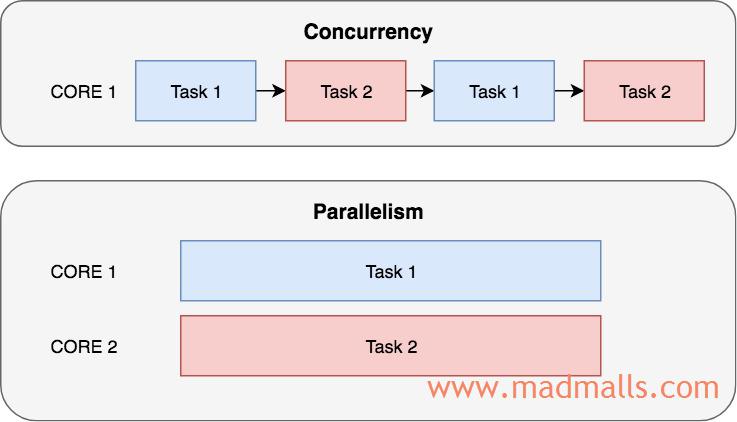
想象一下,你正在做饭和写小说,看起来你好像在同时做这两件事,但你不过是在这两件事之间不断切换而已,当你在等待水煮沸的时候你在写小说,当你要处理蔬菜等食材时你会暂停写小说,这种方式称为 并发,CPU 会快速的切换执行多个任务,由于 CPU 的时钟周期对于人眼来说太快了,以至于你会感觉好像多个任务是同时在执行一样,就好比你可以同时在电脑上看电影和与朋友进行网络聊天。要实现 并行,必须有多核 CPU。就好像有两个人,一个烹饪,另一个同时写小说
1.3 并发编程的方式
Python 中如何实现 并发编程(concurrent programming),即 Do Multiple Things At Once:
- 多进程
- 多线程
- 异步编程(asynchronous programming)
2. Processes vs. Threads vs. Async
| Processes | Threads | Async | |
|---|---|---|---|
| Optimize waiting periods | Yes (preemptive) | Yes (preemptive) | No (cooperative) |
| Use all CPU cores | Yes | No | No |
| Scalability | Low (ones/tens) | Medium (hundreds) | High (thousands+) |
| Use blocking standard library functions | Yes | Yes | No |
| GIL interference | No | Some | No |
2.1 Multiple Processes
- 是
抢占式多任务(preemptive),由操作系统调度。The OS does all the multi-tasking work - 多进程是三种并发模式中唯一可以使用多核 CPU 的模式。Only option for multi-core concurrency
2.2 Multiple Threads
- 是
抢占式多任务(preemptive),由操作系统调度。The OS does all the multi-tasking work - Python 默认的解释器 CPython 由于
GIL的存在,不能使用多核 CPU,只能运行在一个核心上。In CPython, the GIL prevents multi-core concurrency
2.3 Asynchronous Programming
- 是
协作式多任务(cooperative),由用户自己决定在程序中切换执行哪一段代码。No OS intervention - 单进程、单线程。One process, one thread
那么,异步编程 是如何实现多任务的呢? 举个例子,有一天国际象棋天才,她同时与 24 个普通选手对弈。假设天才每走一步棋是 5 秒,普通选手每走一步棋是 55 秒,同时每个局棋平均需要 30 个来回分出胜负(天才和普通选手各走 1 步是一个来回),假设天才在各棋局之间走动的时间忽略不计
- 同步对弈 Synchronous
天才与第 1 个普通选手对弈完成后,才开始与第 2 个普通选手对弈,依次类推。每个棋局用时: 30 * (5 + 55 秒) = 30 分钟,24 个对手,就是 24 个棋局,总用时: 24 * 30 分钟 = 12 小时
- 异步对弈 Asychronous
天才先开始第 1 个棋局(与普通选手 1 对弈),天才用了 5 秒走了第 1 步棋,然后,她的对手要花费 55 秒才能下第 1 步。这个时间对天才来说太久了,所以,在第 1 个普通选手思考的期间,天才走向第 2 个棋局,又用 5 秒走了第 1 步棋,接着走向第 3 个棋局,依次类推,天才下完每个棋局的第 1 步要花费: 24 * 5 秒 = 2 分钟
此时,120 秒过去了,第 1 个棋局的普通选手早就走出了第 1 步。当天才又来到他的面前时,天才用了 5 秒,走了第 2 步,而普通选手又要思考怎么走。所以,天才又去第 2 个棋局花费 5 秒下了第 2 步,依次类推
天才走完 30 轮总用时: 30 * 2 分钟 = 1 小时,比同步对弈提高了 12 倍!
异步编程的详细定义:
异步编程 是指在 单线程 中 并发 执行多个任务,当一个任务在等待数据时,它会释放 CPU 资源,转而执行其它任务,通过程序员自己主动切换任务来最小化空闲时间。A style of concurrent programming in which tasks release the CPU during waiting periods, so that other tasks can use it.
3. 如何实现异步?
3.1 Suspend and Resume
- 异步函数能够被
暂停(suspend)和恢复执行(resume)。async functions need the ability to suspend and resume - 异步函数在等待数据时被暂停执行,当数据到达时,又能够在被暂停的位置处恢复执行。a function that enters a waiting period is suspended, and only resumed when the wait is over
3.2 Implement suspend/resume in Python
回调函数- Callback functions基于生成器的协程函数- generator functions(Python 3.4)原生协程- native coroutine,使用async/await关键字(Python 3.5+)greenlet(gevent, Eventlet)
3.3 Scheduling Asychronous Tasks
异步框架需要实现一个调度器,通常叫事件循环(event loop)。async frameworks need a scheduler, usually called "event loop"- 由
事件循环跟踪所有正在运行的任务。the loop keeps track of all the running tasks - 当一个异步函数被
暂停时,控制权将返回给事件循环,然后由事件循环启动或恢复另一个异步函数。when a funtion is suspended, return controls to the loop, which then finds another funtions to start or resume - 这种方式叫做
协作式多任务。this is called "cooperative multi-tasking"
4. 异步 I/O 操作
多进程 或 多线程 方案中,操作系统不可能无上限地增加进程或线程,一方面会占用大量内存,影响系统稳定性;另一方面 上下文切换 的开销也很大,一旦进程或线程的数量过多时,CPU 的大部分时间就花在 上下文切换 上了,真正运行代码的时间就少了,结果是导致性能严重下降
而异步 I/O 框架中,使用 单线程,利用 事件循环,不断地重复 "监控到事件发生 --> 处理事件" 这一过程。同时,还要把每个 阻塞型操作(blocking operation ) 替换成 非阻塞的异步调用(non-blocking asynchronous call),当某个任务中遇到耗时的 I/O 操作时,才会把控制权 交还 给 事件循环,然后 事件循环 会执行另一个任务。这样就可以避免阻塞型调用中止整个应用程序的进程,合理地解决了 CPU 高速执行能力和 I/O 设备的龟速严重不匹配问题
那么 "请求的网络I/O数据已到达" 这类事件怎么通知给 事件循环呢? 这就要用到 I/O多路复用(I/O multiplexing) 模型,也叫 event driven I/O,不同的操作系统提供了不同的 I/O事件通知接口,比如最早的 select 和 poll,后来 BSD 中实现了 kqueue,Linux 则在 2.6 之后实现了 epoll 接口,详情见上一篇博客 Python 3 爬虫|第1章:I/O Models 阻塞/非阻塞 同步/异步。Python 中 select 模块提供了 Low-level I/O multiplexing,而 Python 3.4 开始新增的 selectors 模块则提供了 High-level and efficient I/O multiplexing
Python 3 爬虫|第8章:使用 asyncio 模块实现并发 将要介绍的异步 I/O 框架 asyncio 中的 事件循环 就是基于 selectors 模块,它会根据不同的操作系统平台使用不同的事件循环对象,比如 asyncio.SelectorEventLoop 和 asyncio.ProactorEventLoop(Proactor 只能用于 Windows 系统,使用 IOCP),事件循环对象会根据操作系统自动选择最优的 I/O multiplexing 接口,比如在 Linux 中会自动使用 epoll
异步 I/O 操作 是指,你发起一个 I/O 操作(比如,等待网络图片数据的到来),却不用等它结束,你可以继续去做其它的事情,当它结束时,你会得到通知,然后再回来接着处理这个 I/O 后续的操作。而 同步 I/O 操作 则会被阻塞在 I/O 操作上直到它完成,这期间 CPU 做了很多事,只是没有运行你的程序
注意: Python 标准库中的 阻塞型 函数不支持异步,比如 time.sleep() 和 urllib.request.urlopen() 等会阻塞整个程序,并不会把控制权交还给事件循环。异步框架中需要实现对应的 非阻塞型 的异步操作函数,如 asyncio.sleep() 和 aiohttp.request() 等
代码已上传到 https://github.com/wangy8961/python3-concurrency ,欢迎 star







0 条评论
评论者的用户名
评论时间暂时还没有评论.