
Go基础|第12章:并发

Synopsis: 并发(concurrency)不是并行(parallelism),并行是让不同的代码片段同时在不同的 CPU 核上执行。并行的关键是同时执行多个任务,而并发是指同时管理很多任务,这些任务可能只做了一半就被暂停去做别的任务了。在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时处理很多任务。这种 [使用较少的资源做更多的事情] 的哲学, 也是指导 Go 语言设计的哲学。Go 语言里的并发指的是能让某个函数独立于其他函数运行的能力。当一个函数被创建为 goroutine 时,Go 会将其视为一个独立的工作单元
1. goroutine
A goroutine is a lightweight thread(User-level thread) managed by the Go runtime.
通过 go 关键字,Go 运行时调度器会创建一个新的 goroutine (或者从存放空闲的 goroutines 的队列中获取一个)并执行函数,比如:
和调用其他函数一样,创建 goroutine 的函数调用可以传参,不过 goroutine 结束时无法获取函数的返回值(可以使用 channel)。其中 f, x, y 的求值发生在当前 goroutine 中(比如程序启动时 main 函数所在的 main goroutine),而 f 的执行发生在新建的 goroutine 中
package main import ( "log" "time" ) // main is the entry point for all Go programs. func main() { log.Println("Start Goroutines") greetings := []string{"你好", "Madman"} for i, v := range greetings { // Create a goroutine. Run the anonymous function concurrently; don’t wait for it. go func(index int, greeting string) { // For strings, the range loop iterates over Unicode code points. for _, char := range greeting { time.Sleep(1 * time.Second) // 模拟耗时操作 log.Printf("goroutine %d: %c\n", index, char) } }(i+1, v) // 注意:参数求值发生在当前 main goroutine 的 for 循环中,这里将 i 和 v 作为显式的参数传入,来避免 [循环变量快照] 的问题 } log.Println("Terminating Program") // At this point the program execution stops and all active goroutines are killed. } /* Output: 2019/01/12 14:03:14 Start Goroutines 2019/01/12 14:03:14 Terminating Program */
上例中,main() 函数返回时程序就结束了,不会等待其它 goroutine 执行完毕,如果我们故意让 main goroutine 睡一会:
package main import ( "log" "time" ) // main is the entry point for all Go programs. func main() { log.Println("Start Goroutines") greetings := []string{"你好", "Madman"} for i, v := range greetings { // Create a goroutine. Run the anonymous function concurrently; don’t wait for it. go func(index int, greeting string) { // For strings, the range loop iterates over Unicode code points. for _, char := range greeting { time.Sleep(1 * time.Second) // 模拟耗时操作 log.Printf("goroutine %d: %c\n", index, char) } }(i+1, v) } // Give the other goroutine time to finish time.Sleep(10 * time.Second) log.Println("Terminating Program") } /* Output: 2019/01/12 14:04:07 Start Goroutines 2019/01/12 14:04:08 goroutine 1: 你 2019/01/12 14:04:08 goroutine 2: M 2019/01/12 14:04:09 goroutine 2: a 2019/01/12 14:04:09 goroutine 1: 好 2019/01/12 14:04:10 goroutine 2: d 2019/01/12 14:04:11 goroutine 2: m 2019/01/12 14:04:12 goroutine 2: a 2019/01/12 14:04:13 goroutine 2: n 2019/01/12 14:04:17 Terminating Program */
执行两个 goroutine 的总耗时为 6 秒,而不是 2 + 6 秒,并发执行! 关于 Go 运行时调度器如何创建 goroutine 并管理其运行,可以参考 Go runtime scheduler: M-P-G 模型
通常,我们使用 sync.WaitGroup 来让 main goroutine 等待其它 goroutine 完成,而不是使用睡眠 ^_^
2. channel
All goroutines in a single program run in the same address space, so access to shared memory must be synchronized.
Go 语言的并发同步模型来自一个叫作 通信顺序进程(Communicating Sequential Processes,CSP) 的范型(paradigm)。CSP 是一种 消息传递 模型,通过在 goroutine 之间传递数据来传递消息,而不是对数据进行加锁来实现同步访问。Don't communicate by sharing memory, share memory by communicating.
2.1 通道类型
用于在 goroutine 之间同步和传递数据的关键数据类型叫作 通道(channel),声明通道时,需要指定将要被共享的数据的类型,可以通过通道共享内建基本类型、命名类型、结构体类型和引用类型的值或者指针:
chan T:共享数据类型为 T 类型的双向(bi-directional)通道,可以向通道发送数据,也可以从通道接收数据chan<- T:共享数据类型为 T 类型的单向发送通道,只能向通道发送数据,不能从通道接收数据<-chan T:共享数据类型为 T 类型的单向接收通道,只能从通道接收数据,不能向通道发送数据
双向通道
chan T的值可以被隐式地转换为单向通道类型chan<- T和<-chan T,但反之不行!任何双向通道值被赋值给向单向通道变量时,都将导致该隐式转换
Go 语言中需要使用内建函数 make() 来创建一个通道:
创建通道时,make() 函数的第一个参数必须是关键字 chan,后面是通道共享数据的类型。如果创建的是一个带缓冲的通道,还需要指定第二个参数,表示这个通道的缓冲区大小
可以使用通道操作符 <- 来发送或者接收值,箭头的方向就是数据流的方向:
ch <- v // send v to channel ch 此时 <- 是二元运算符(binary operator) v := <-ch // receive from ch, and assign value to v 此时 <- 是一元运算符(unary operator)
通道是否带带缓冲,其行为会有一些不同,理解这个差异对决定到底应该使用无缓冲的通道还是带缓冲的通道很有帮助
2.2 无缓冲通道
无缓冲的通道(unbuffered channel) 是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送方和接收方同时准备好,才能完成发送或接收操作。如果两个 goroutine 没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。对无缓冲的通道进行发送或接收的交互行为本身就是同步的:
package main import "fmt" func sum(s []int, c chan int) { sum := 0 for _, v := range s { sum += v } c <- sum // send sum to c } func main() { s := []int{7, 2, 8, -9, 4, 0} c := make(chan int) // create an unbuffered channel of int go sum(s[:len(s)/2], c) go sum(s[len(s)/2:], c) x, y := <-c, <-c // receive from c fmt.Printf("x = %v, y = %v\n", x, y) fmt.Printf("x + y = %v", x+y) } /* Output: x = -5, y = 17 x + y = 12 */
2.3 带缓冲通道
带缓冲的通道(buffered channel) 是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收:
- 只有在通道的缓冲区被填满时,发送动作才会阻塞
- 只有在通道的缓冲区为空时,接收动作才会阻塞
这导致带缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;带缓冲的通道没有这种保证
package main import "fmt" func main() { ch := make(chan int, 2) ch <- 1 ch <- 2 // ch <- 3 fmt.Println(<-ch) fmt.Println(<-ch) // fmt.Println(<-ch) } /* Output: 1 2 */
如果取消第 10 行或第 14 行的注释,那么程序会报错 fatal error: all goroutines are asleep - deadlock!,因为此程序只有一个 main goroutine,一旦它被阻塞了,就表示陷入死锁了
采用最快响应(The first response wins) 特别适合使用带缓冲的通道:
func request(hostname string) (response string) { /* ... */ } func mirroredQuery() string { responses := make(chan string, 3) go func() { responses <- request("asia.gopl.io") }() go func() { responses <- request("europe.gopl.io") }() go func() { responses <- request("americas.gopl.io") }() return <-responses // return the quickest response }
上面的示例中的 mirroredQuery() 函数并发地向三个镜像站点发出请求,三个镜像站点分散在不同的地理位置,它们分别将响应发送到带缓存的通道中。最后接收方 mirroredQuery() 只接收第一个收到的响应,也就是最快的那个响应。因此 mirroredQuery() 函数可能在另外两个速度慢的镜像站点响应之前就返回了结果
注意:如果有 N 个数据源,为了防止被舍弃的响应所对应的 goroutine 永久阻塞,那么用于传输数据的通道必须为带缓存的通道,且通道容量至少为 N-1
2.4 发送方关闭通道
发送方可通过内建函数 close() 来关闭一个通道,表示没有需要发送的值了:
通道被关闭后:
- 接收方对
无缓冲通道进行读取操作永远不会阻塞,获取的值为通道的共享数据类型的零值 - 接收方对
带缓冲通道进行读取操作永远不会阻塞,等读取完通道缓冲区中的所有值之后,获取的值为通道的共享数据类型的零值
可以为接收表达式指定第二个参数来测试通道是否被关闭:
如果没有值可以接收且通道已被关闭时,ok 会被设置为 false:
package main import ( "fmt" ) func fibonacci(n int, c chan int) { x, y := 0, 1 for i := 0; i < n; i++ { c <- x x, y = y, x+y } close(c) } func main() { c := make(chan int) go fibonacci(10, c) // 或者声明为带缓冲的通道 // c := make(chan int, 10) // go fibonacci(cap(c), c) for { v, ok := <-c if !ok { break } fmt.Println(v) } } /* Output: 0 1 1 2 3 5 8 13 21 34 */
建议 只让发送方去关闭通道,任何时候都不要让接收方去关闭通道,以下情形会产生 panic 错误:
- 尝试关闭一个 nil 通道
- 尝试关闭一个已经关闭的通道
- 向一个已经关闭的通道发送数据
注意:通道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收方不再有需要发送的值时,才有必要关闭通道!比如一个发送方和多个接收方,发送方通过关闭无缓冲的通道来
广播(broadcast a signal)通知所有接收方
2.4 for-range
循环 for i := range ch 会不断从信道接收值,直到它被关闭。上面的示例可以简写为:
package main import ( "fmt" ) func fibonacci(n int, c chan int) { x, y := 0, 1 for i := 0; i < n; i++ { c <- x x, y = y, x+y } close(c) } func main() { c := make(chan int) go fibonacci(10, c) // 或者声明为带缓冲的通道 // c := make(chan int, 10) // go fibonacci(cap(c), c) for i := range c { fmt.Println(i) } }
2.5 select 多路复用
The select statement lets a goroutine wait on multiple communication operations(eg. wait on a group of channels).
它会阻塞到某个分支可以继续执行为止,当多个分支都准备好时会随机选择一个执行:
package main import "fmt" func fibonacci(c, quit chan int) { x, y := 0, 1 for { select { case c <- x: // 尝试发送值 x, y = y, x+y case <-quit: // 等待接收方的信号,如果解除阻塞,表示接收方不需要额外的值了 fmt.Println("quit") return } } } func main() { c := make(chan int) quit := make(chan int) // 仅是用于两个 goroutine 之间的同步,发送通知信号 go func() { for i := 0; i < 10; i++ { fmt.Println(<-c) // 尝试接收值 } quit <- 0 // 不需要额外的值了,通知发送方 }() fibonacci(c, quit) } /* Output: 0 1 1 2 3 5 8 13 21 34 quit */
为了在尝试发送或者接收时不发生阻塞,可使用 default 分支。当 select 中的其它分支都没有准备好时,default 分支就会执行:
quit := make(chan int)创建用于发送信号的通道,或者可以使用quit := make(chan struct{}),空结构体类型的值为struct{}{},它占用的内存空间是 0 字节。确切地说,这个值在整个 Go 程序中永远都只会存在一份。所以我们可以无数次地使用这个值,但是用到的却都是同一个值
time.Tick 和 time.After 会返回一个通道,下面的示例可实现周期性轮询,并在超时时间后退出:
time.Tickreturns a channel that delivers clock ticks at even intervalstime.Afterwaits for a specified duration and then sends the current time on the returned channel
package main import ( "fmt" "time" ) func main() { tick := time.Tick(100 * time.Millisecond) boom := time.After(500 * time.Millisecond) for { select { case <-tick: fmt.Println("tick.") case <-boom: fmt.Println("BOOM!") return default: fmt.Println(" .") time.Sleep(50 * time.Millisecond) } } } /* Output: . . tick. . . tick. . . tick. . . tick. . . tick. BOOM! */
select {}语句:永久阻塞当前 goroutine,常用于 main() 函数末尾!
Sending or receiving from a nil channel blocks forever. 所以,可以用 nil 来激活或者禁用 case:
var ch1 chan int // zero value: nil, disables this channel select { case <-ch1: fmt.Println("Received from ch1") // will not happen case <-ch2: fmt.Println("Received from ch2") }
3. sync.WaitGroup
A sync.WaitGroup waits for a group of goroutines to finish.
wg sync.WaitGroup 是一个计数信号量,可以用来记录并维护运行的 goroutine,使用 wg.Add(delta int) 来增加 wg 维护的计数。如果 wg 的值大于 0,那么 wg.Wait() 方法就会阻塞。为了减小 wg 的值并最终释放 main() 函数,要使用 defer 声明在函数退出时调用 wg.Done() 方法。我们来改写本文章节 1 中的示例:
package main import ( "log" "sync" "time" ) // main is the entry point for all Go programs. func main() { log.Println("Start Goroutines") var wg sync.WaitGroup // Note: A WaitGroup must not be copied after first use. greetings := []string{"你好", "Madman"} for i, v := range greetings { // Set the number of goroutines to wait for wg.Add(1) // Create a working goroutine. Run hello() concurrently; don’t wait for it. go func(index int, greeting string) { // The new goroutine run and call Done() when finished defer wg.Done() // For strings, the range loop iterates over Unicode code points. for _, char := range greeting { time.Sleep(1 * time.Second) // 模拟耗时操作 log.Printf("goroutine %d: %c\n", index, char) } }(i+1, v) } // Wait() is used to block until the other goroutines have finished wg.Wait() log.Println("Terminating Program") } /* Output: 2019/01/12 14:25:00 Start Goroutines 2019/01/12 14:25:01 goroutine 1: 你 2019/01/12 14:25:01 goroutine 2: M 2019/01/12 14:25:02 goroutine 2: a 2019/01/12 14:25:02 goroutine 1: 好 2019/01/12 14:25:03 goroutine 2: d 2019/01/12 14:25:04 goroutine 2: m 2019/01/12 14:25:05 goroutine 2: a 2019/01/12 14:25:06 goroutine 2: n 2019/01/12 14:25:06 Terminating Program */
注意:
sync.WaitGroup值不能被复制!
4. data race
goroutine 是用户级线程,Go 应用(进程)中的多个 goroutine 属于相同的地址空间,所以访问内存中的共享资源时必须使用 同步 机制!
无论任何时候,如果两个或者多个 goroutine 在没有互相同步的情况下并发访问同一变量,且至少其中的一个是写操作的时候就会发生 数据竞争(data race)
一般情况下,我们没法确定分别位于两个 goroutine 中的事件发生的先后顺序!所以,对一个共享资源的读和写操作必 须是原子化的,换句话说,同一时刻只能有一个 goroutine 对共享资源进行读和写操作
下面是一个包含 竞争状态(race candition) 的示例程序:
package main import ( "fmt" "runtime" "sync" ) var ( // counter is a variable incremented by all goroutines. counter int // wg is used to wait for the program to finish. wg sync.WaitGroup ) // incCounter increments the package level counter variable. func incCounter(id int) { // Schedule the call to Done to tell main we are done. defer wg.Done() for count := 0; count < 2; count++ { // Capture the value of Counter. value := counter // Gosched yields the processor, allowing other goroutines to run. It does not // suspend the current goroutine, so execution resumes automatically. // 在两次操作中间这样做的目的是强制调度器切换两个 goroutine,以便让竞争状态的效果变得更明显 runtime.Gosched() // Increment our local value of Counter. value++ // Store the value back into Counter. counter = value } } // main is the entry point for all Go programs. func main() { // Add a count of two, one for each goroutine. wg.Add(2) // Create two goroutines. go incCounter(1) go incCounter(2) // Wait for the goroutines to finish. wg.Wait() fmt.Println("Final Counter:", counter) } /* Output: Final Counter: 2 */
变量 counter 会进行 4 次读和写操作,每个 goroutine 执行两次。但是,程序终止时,counter 变量的值却是 2 ?
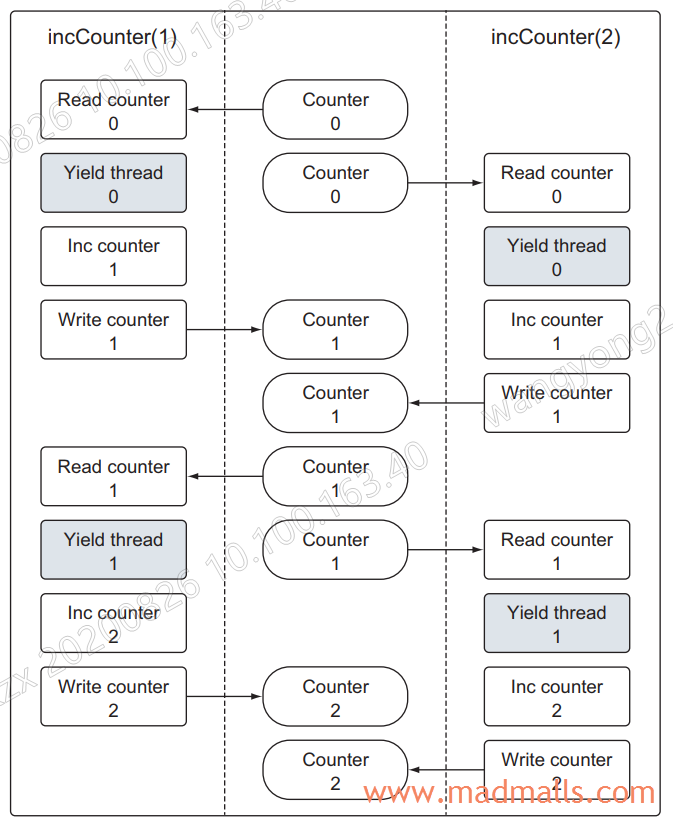
可以在 go build、go run 或者 go test 命令后面加上 -race 的 flag 来检测竞争状态:
D:\GoCodes\hello>go run -race hello.go
==================
WARNING: DATA RACE
Read at 0x000001131b88 by goroutine 8:
main.incCounter()
D:/GoCodes/hello/hello.go:24 +0x84
Previous write at 0x000001131b88 by goroutine 7:
main.incCounter()
D:/GoCodes/hello/hello.go:35 +0xa5
Goroutine 8 (running) created at:
main.main()
D:/GoCodes/hello/hello.go:46 +0x90
Goroutine 7 (finished) created at:
main.main()
D:/GoCodes/hello/hello.go:45 +0x6f
==================
Final Counter: 4
Found 1 data race(s)
exit status 66
消除竞争状态的一种办法是使用 Go 语言提供的锁机制,来锁住共享资源,从而保证 goroutine 的同步状态
5. 锁住共享资源
如果需要顺序访问一个整型变量或者一段代码,标准库 atomic 和 sync 包里的函数提供了很好的解决方案
5.1 原子操作
// This sample program demonstrates how to use the atomic // package to provide safe access to numeric types. package main import ( "fmt" "runtime" "sync" "sync/atomic" ) var ( // counter is a variable incremented by all goroutines. counter int64 // wg is used to wait for the program to finish. wg sync.WaitGroup ) // main is the entry point for all Go programs. func main() { // Add a count of two, one for each goroutine. wg.Add(2) // Create two goroutines. go incCounter(1) go incCounter(2) // Wait for the goroutines to finish. wg.Wait() // Display the final value. fmt.Println("Final Counter:", counter) } // incCounter increments the package level counter variable. func incCounter(id int) { // Schedule the call to Done to tell main we are done. defer wg.Done() for count := 0; count < 2; count++ { // Safely Add One To Counter. atomic.AddInt64(&counter, 1) // Gosched yields the processor, allowing other goroutines to run. It does not // suspend the current goroutine, so execution resumes automatically. // 在两次操作中间这样做的目的是强制调度器切换两个 goroutine,以便让竞争状态的效果变得更明显 runtime.Gosched() } } /* Output: Final Counter: 4 */
atmoic.AddInt64() 函数会同步整型值的加法,强制同一时刻只能有一个 goroutine 运行并完成这个加法操作。当 goroutine 试图去调用任何原子函数时,这些 goroutine 都会自动根据所引用的变量做同步处理,现在我们得到了正确的值 4
针对 int64 类型,另外两个有用的原子函数是 atmoic.LoadInt64() 和 atmoic.StoreInt64(),这两个函数提供了一种安全地读和写一个整型值的方式:
package main import ( "fmt" "sync" "sync/atomic" "time" ) var ( // shutdown is a flag to alert running goroutines to shutdown. shutdown int64 // wg is used to wait for the program to finish. wg sync.WaitGroup ) // doWork simulates a goroutine performing work and // checking the Shutdown flag to terminate early. func doWork(name string) { // Schedule the call to Done to tell main we are done. defer wg.Done() for { fmt.Printf("Doing %s Work\n", name) time.Sleep(250 * time.Millisecond) // Do we need to shutdown. if atomic.LoadInt64(&shutdown) == 1 { fmt.Printf("Shutting %s Down\n", name) break } } } // main is the entry point for all Go programs. func main() { // Add a count of two, one for each goroutine. wg.Add(2) // Create two goroutines. go doWork("A") go doWork("B") // Give the goroutines time to run. time.Sleep(1 * time.Second) // Safely flag it is time to shutdown. fmt.Println("Shutdown Now") atomic.StoreInt64(&shutdown, 1) // Wait for the goroutines to finish. wg.Wait() } /* Output: Doing A Work Doing B Work Doing A Work Doing B Work Doing A Work Doing B Work Doing A Work Doing B Work Doing A Work Shutdown Now Shutting B Down Shutting A Down */
针对 int64 类型,还有 SwapInt64() 和 CompareAndSwapInt64() 两个函数,分别提供了一种安全地交换、比较并交换一个整型值的方式
原子操作能够保证原子性(atomicity),它在执行过程中不会被中断(interrupt),因为它在底层由 CPU 提供芯片级的支持,所以绝对有效。正是因为原子操作不能被中断,所以它需要足够简单,并且要求快速,它的执行速度要比其它同步工具快得多,通常会高出好几个数量级
由于原子操作函数只支持非常有限的数据类型(int32、int64、uint32、uint64、uintptr、unsafe.Pointer),所以在很多应用场景下,使用互斥锁往往更加适合
5.2 互斥锁
另一种同步访问共享资源的方式是使用 互斥锁(Mutex),互斥锁这个名字来自 互斥(mutual exclusion) 的概念。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个 goroutine 可以执行这个临界区里的代码
Go 标准库中提供了 sync.Mutex 互斥锁类型及其两个方法:Lock() 和 Unlock(),我们可以通过在代码前调用 Lock 方法,在临界区代码之后调用 Unlock 方法来保证一段代码的互斥执行,也可以用 defer 语句来保证互斥锁一定会被解锁:
package main import ( "fmt" "runtime" "sync" ) var ( // counter is a variable incremented by all goroutines. counter int // wg is used to wait for the program to finish. wg sync.WaitGroup // mu is used to define a critical section of code. mu sync.Mutex ) // incCounter increments the package level Counter variable // using the Mutex to synchronize and provide safe access. func incCounter(id int) { // Schedule the call to Done to tell main we are done. defer wg.Done() for count := 0; count < 2; count++ { // Only allow one goroutine through this // critical section at a time. mu.Lock() { // Capture the value of counter. value := counter // Gosched yields the processor, allowing other goroutines to run. It does not // suspend the current goroutine, so execution resumes automatically. // 在两次操作中间这样做的目的是强制调度器切换两个 goroutine,以便让竞争状态的效果变得更明显 runtime.Gosched() // Increment our local value of counter. value++ // Store the value back into counter. counter = value } mu.Unlock() // Release the lock and allow any // waiting goroutine through. } } // main is the entry point for all Go programs. func main() { // Add a count of two, one for each goroutine. wg.Add(2) // Create two goroutines. go incCounter(1) go incCounter(2) // Wait for the goroutines to finish. wg.Wait() fmt.Printf("Final Counter: %d\n", counter) } /* Output: Final Counter: 4 */
使用互斥锁时有哪些注意事项?
- 不要重复锁定互斥锁,对一个已经被锁定的互斥锁进行锁定时,会立即阻塞当前 goroutine
- 不要忘记解锁互斥锁,必要时使用
defer语句 - 不要对尚未锁定或者已解锁的互斥锁解锁
- 不要在多个函数之间直接传递互斥锁。如果你把一个互斥锁作为参数值传给一个函数(会传递副本),那么在这个函数中对传入的互斥锁的所有操作,都不会对存在于该函数之外的那个原锁产生任何的影响,这样就失去了互斥锁的效果!
5.3 读写锁
读写锁 sync.RWMutex 是多读单写互斥锁的简称,它对共享资源的读操作和写操作进行区别对待。相比于互斥锁,读写锁可以实现更加细腻的访问控制。一个读写锁中实际上包含了两个锁:
- 写锁,
Lock()方法和Unlock()方法分别用于对写锁进行锁定和解锁 - 读锁,
RLock()方法和RUnlock()方法分别用于对读锁进行锁定和解锁
读写锁的规则如下:
- 在写锁已被锁定的情况下再试图锁定写锁(想进行多个写操作时),会阻塞当前 goroutine
- 在写锁已被锁定的情况下试图锁定读锁(想进行写操作的同时进行读操作时),也会阻塞当前 goroutine
- 在读锁已被锁定的情况下试图锁定写锁(想进行读操作的同时进行写操作时),同样会阻塞当前 goroutine
- 在读锁已被锁定的情况下再试图锁定读锁(想进行多个读操作时),
不会阻塞当前 goroutine
即,对于某个受到读写锁保护的共享资源,多个写操作不能同时进行,写操作和读操作也不能同时进行,但多个读操作却可以同时进行,特别适合读多写少的情形
读写锁对 写操作 之间的互斥,其实是通过它内含的一个互斥锁实现的。因此,也可以说,Go 语言的读写锁是互斥锁的一种扩展,所以它也沿用了互斥锁的行为模式,比如不要重复锁定读锁或写锁、不要对尚未锁定或者已解锁的读锁或写锁进行解锁
package main import ( "fmt" "sync" "time" ) // SafeCounter 的并发使用是安全的 type SafeCounter struct { v map[string]int mux sync.RWMutex } // Inc 增加给定 key 的计数器的值 func (c *SafeCounter) Inc(key string) { c.mux.Lock() c.v[key]++ c.mux.Unlock() } // Value 返回给定 key 的计数器的当前值 func (c *SafeCounter) Value(key string) int { c.mux.RLock() defer c.mux.RUnlock() return c.v[key] } func main() { c := SafeCounter{v: make(map[string]int)} for i := 0; i < 100000; i++ { go c.Inc("somekey") } time.Sleep(time.Second) fmt.Println(c.Value("somekey")) // 100000 }







0 条评论
评论者的用户名
评论时间暂时还没有评论.