
sed - 文本分析与转换工具 (1) 入门

Synopsis: sed(意为流编辑器,源自英语“stream editor”的缩写)是类Unix系统中用来在一个输入流(文件或者管道中的输入)执行基本的文本过滤和转换的工具,它是非交互式的(不同于vim),同时又是面向字符流的,输入的字符流经过一个或多个有顺序的sed操作指令处理后,输出到stdout或与输入文件不同的其它文件中。你可以使用sed在不打开文件的情况下,从指定位置处开始编辑、文本替换、删除或选择性输出文本内容
sed系列:
- sed - 文本分析与转换工具 (1) 入门 [current]
- sed - 文本分析与转换工具 (2) 进阶
- sed - 文本分析与转换工具 (3) 实战
1. 初步认识
sed命令的基本格式为sed [options] SCRIPT INPUTFILE...,默认情况下sed会依次处理输入文件的每一行,除非限定了地址范围(还是会读取每一行,但只对匹配的行应用操作命令)。
SCRIPT至少要包括一个操作指令,不然sed只会原样输出文件内容到屏幕那样没有意义,而每条操作指令instruction都由地址addresses和命令commands组成(建议每条指令都用引号引起来,这样可避免shell对诸如空格、$等特殊字符的处理,此规则同样适应于grep和awk),只有地址或地址范围匹配成功,才会执行后面的命令。多条操作指令用;隔开或者使用-e选项每次指定一条操作指令。操作指令中的命令如果有多个,需要用{}包括起来,同时命令之间用;隔开。多个地址可以使用{}嵌套(即多重匹配条件)。
1. 原样输出 # sed '' /etc/passwd 2. 只打印最后一行,-n是选项,默认情况下sed会依次输出每一行到stdout,-n选项会禁止sed输出。'$ p'整体是操作指令,其中$是单个地址,表示文件最后一行;p是命令,表示打印pattern space中的内容到stdout。所以整行sed命令就是先用-n禁止sed输出,再用'$ p'只输出指定行的内容 # sed -n '$ p' /etc/passwd 3. 如果省略地址,则命令将应用于文件的每一行上 # sed -n 'p' /etc/passwd 4. 必须指定命令,否则sed会报错 # sed -n '1,5' /etc/passwd sed: -e expression #1, char 3: missing command 5. 多个操作指令,以冒号分隔多条指令,外面再用大括号包括起来 # sed -n '{ 1 p ; /mail/ p }' /etc/passwd 或者使用-e选项 # sed -n -e '1 p' -e '/mail/ p' /etc/passwd 6. 一个操作指令中有多个命令,先输出行号再打印行内容 # sed -n '/nologin/ { = ; p }' /etc/passwd 7. 多个地址嵌套,第1至10行中,包含nologin字串的行,先输出行号再打印行内容 # sed -n '1,10 { /nologin/ { = ; p } }' /etc/passwd
如果没有指定-e或-f选项,那么第一个非选项参数被视为SCRIPT,其它非选项参数被视为输入文件。下面的命令是等价的,都是把字符串hello替换为world :
# sed 's/hello/world/' input.txt > output.txt # sed -e 's/hello/world/' input.txt > output.txt # sed --expression='s/hello/world/' input.txt > output.txt # echo 's/hello/world/' > myscript.sed # sed -f myscript.sed input.txt > output.txt # sed --file=myscript.sed input.txt > output.txt
如果没有指定输入文件或者用-代表INPUTFILE,sed都会从标准输入stdin读取数据
# sed 's/hello/world/' input.txt > output.txt # sed 's/hello/world/' < input.txt > output.txt # cat input.txt | sed 's/hello/world/' - > output.txt
2. 处理流程
sed的工作流可以归结为读取、执行操作指令、输出三个步骤
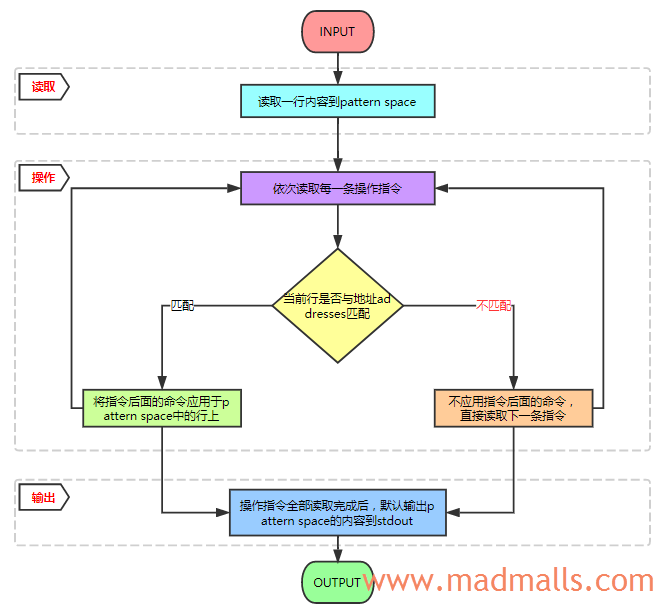
说明:
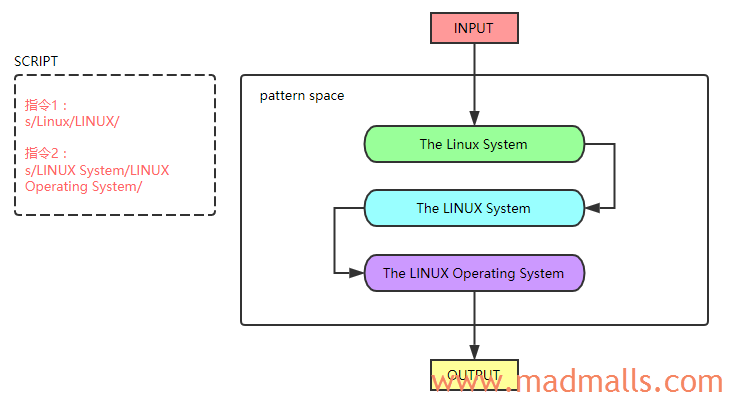
READ: sed从输入流(文件或者管道中的输入)中读取一行内容,删除尾部的换行符,并把它缓存到一个被称为pattern space的空间内,接下来的所有操作只会影响缓存区的内容,所以默认情况下,sed并不会修改输入文件的内容,可以添加-i选项以in-a-place方式直接修改输入文件EXECUTE: 执行第一条操作指令,判断pattern space空间的内容是否与指令的模式匹配,如果匹配则执行该指令中的命令,完成后,再取下一条操作指令,此时pattern space空间的内容已经被修改,下一条指令是作用于上一条指令修改后的内容上的;如果不匹配,则直接取下一条操作指令,继续判断是否匹配。注意,操作指令是按顺序作用于pattern space中的内容上的,所以操作指令的顺序很重要DISPLAY: 当所有操作指令都被判断执行与否后,如果没有指定-n选项,默认情况下sed将会把修改后的pattern space内容输出到stdout,之后清空pattern space
3. 常用选项
3.1 基本选项
(1) -n, --quiet, --silent
默认情况下,pattern space中的内容在处理完成后将会打印到标准输出,该选项用于阻止该行为
(2) -e script, --expression=script
该选项指明后面是操作指令,如果sed命令的SCRIPT只有一个操作指令时,可以省略-e选项。多个操作指令时,每个指令前添加-e选项
1. 省略-e选项 # sed -n '1 p' /etc/passwd 2. 多个操作指令 # sed -n -e '1 p' -e '/mail/ p' /etc/passwd 3. 多个操作指令的另一种写法,以冒号分隔多条指令,外面再用大括号包括起来 # sed -n '{ 1 p ; /mail/ p }' /etc/passwd 4. 如果多个操作指令是每行书写时,可以省略冒号和大括号 # sed -n ' > 1p > /mail/p > ' /etc/passwd
(3) -f script-file, --file=script-file
指定包含要执行的操作指令的脚本文件
3.2 GNU sed特有选项
(1) -i[SUFFIX], --in-place[=SUFFIX]
sed默认不会将操作指令的结果应用到文件内容上,只是修改pattern space空间的内容,即不会修改文件内容。-i选项会直接修改文件内容,如果指定了SUFFIX,则会先备份原文件,再修改文件内容
























分享
相关推荐






作者
发表评论
专题系列






0 条评论
评论者的用户名
评论时间暂时还没有评论.