
awk - 数据提取和报告工具 (1) 入门

Synopsis: awk是一种解释型编程语言。它非常强大,专为文本处理而设计。它的名字来源于其三位作者的姓氏 - Alfred Aho,Peter Weinberger和Brian Kernighan。awk通常用作数据提取和报告工具,例如生成格式化报告。awk语言广泛使用字符串数据类型,关联数组(即按键字符串索引的数组)和正则表达式。程序由一系列规则rule组成(程序也可能包含用户自定义的函数), 每个规则指定一个要搜索的模式pattern和匹配到模式后的动作action,模式和动作至少要指定一个。如果省略pattern,则action将应用于每一条记录(通常是每一行);如果省略action,默认是{ print $0 }将当前记录整体打印输出
awk系列:
- awk - 数据提取和报告工具 (1) 入门 [current]
- awk - 数据提取和报告工具 (2) 进阶
- awk - 数据提取和报告工具 (3) 函数
- awk - 数据提取和报告工具 (4) 实战
1. 初步认识
既然awk的基本功能是匹配文本并处理,那么当你运行awk时,你需要指定一个awk程序program来告诉awk该做什么。该程序由一系列规则rule组成(程序也可能包含用户自定义的函数,本文最后会讲), 每个规则指定一个要搜索的模式pattern和匹配到模式后的动作action,模式和动作至少要指定一个。如果省略pattern,则action将应用于每一条记录(通常是每一行);如果省略action,默认是{ print $0 }将当前记录整体打印输出。
多条规则默认使用换行符分隔(如果awk是写在shell命令行中的一整行,多条规则用空白字符分隔)。所有动作语句用大括号{ }包括起来,以将其与模式分隔开,如果有多个动作语句,使用;分号分隔。
在awk语言中,注释以#开头,并且一直延续到行尾, #不一定是该行的第一个字符。
Linux系统中使用的是GNU awk,awk命令其实是指向gawk的软链接
# whereis awk awk: /usr/bin/awk /usr/libexec/awk /usr/share/awk /usr/share/man/man1/awk.1.gz /usr/share/man/man1p/awk.1p.gz # ls -l /usr/bin/awk lrwxrwxrwx. 1 root root 4 Aug 10 2017 /usr/bin/awk -> gawk
1.1 语法
(1) awk命令行
有几种方法可以运行awk程序, 如果程序很短,将它包含在运行awk的命令中是最简单的,如下所示:
如果是在shell命令行中,建议使用单引号' '包括整个awk程序,因此shell不会将任何awk字符解释为特殊的shell字符( 引号还会告诉shell将所有程序视为awk的单个参数,并允许程序长度超过一行)。
(2) awk程序文件
当程序很长时,将它放在一个文件中并使用像这样的命令运行通常会更方便:
不指定输入文件时,awk将读取标准输入(管道,或者键盘上输入的内容,以Ctrl-d结束输入),以下示例实现类似于cat命令的效果:
(3) awk脚本
还可以创建可独立运行的awk脚本:
1. 脚本内容 # cat advice #! /bin/awk -f BEGIN { print "Don't Panic!" } 2. 执行 # chmod +x advice # ./advice Don't Panic!
1.2 执行过程
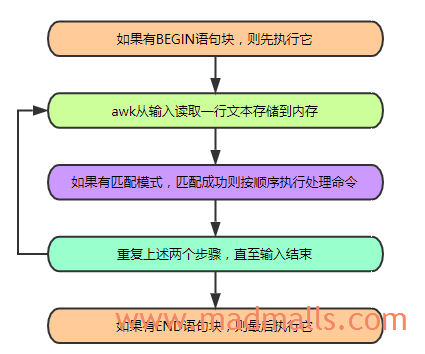
说明:
读取: awk从输入流(文件,管道或stdin)中读取一行并将其存储在内存中处理: 如果该行内容匹配指定的特定模式时,awk就会按顺序在该行执行指定的命令。如果没有指定匹配模式,默认情况下awk在每一行执行命令循环: 重复读取和处理步骤,直至输入文件结束
1.3 记录record和字段field
准确的来说,awk是每次读取一条记录record到内存,然后处理它。因为awk中默认的记录分隔符RS是换行符\n,所以通常以文件的每一行表示一条记录。
同时,awk又把记录分隔成多个字段field,默认的字段分隔符FS是空白字符。记录和字段的概念类似于关系数据库中行和列的关系。
$0表示当前整行内容$1、$2... 依次表示第1个字段值、第2个字段值...$NFNF是当前正在处理的记录的字段数,所以$NF代表最后一个字段,$(NF-1)代表倒数第二个字段
1. 可以通过修改awk内置变量 RS 来更改记录的分割符 # awk '{ print $0 }' /etc/passwd | head -n 3 root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin # awk 'BEGIN { RS=":" } { print $0 }' /etc/passwd | head -n 3 root x 0 2. 可以通过修改awk内置变量 FS 来更改记录的分割符。默认字段分隔符是空白字符,所以/etc/passwd只有一个字段; 如果改成冒号分隔,就有7个字段,$1表示第1个字段用户名 # awk '{ print $1 }' /etc/passwd | head -n 3 root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin # awk 'BEGIN { FS=":" } { print $1 }' /etc/passwd | head -n 3 root bin daemon
1.4 常用的pattern
(1) BEGIN程序块(可选)
BEGIN block的语法是BEGIN {awk-commands},其中BEGIN是特殊的pattern,后面是一系列action。BEGIN block只在awk程序启动时执行一次(处理第一个记录前),一般在这里初始化变量或输出表格的头部信息。 BEGIN是awk关键字,因此它必须大写。
1. 演示用的数据文件,邮件列表,包含姓名/电话/email/关系代码(A:熟人,F:朋友,R:亲戚) # cat mail-list Amelia 555-5553 amelia.zodiacusque@gmail.com F Anthony 555-3412 anthony.asserturo@hotmail.com A Becky 555-7685 becky.algebrarum@gmail.com A Bill 555-1675 bill.drowning@hotmail.com A Broderick 555-0542 broderick.aliquotiens@yahoo.com R Camilla 555-2912 camilla.infusarum@skynet.be R Fabius 555-1234 fabius.undevicesimus@ucb.edu F Julie 555-6699 julie.perscrutabor@skeeve.com F Martin 555-6480 martin.codicibus@hotmail.com A Samuel 555-3430 samuel.lanceolis@shu.edu A Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R 2. 演示用的数据文件,发货量,包含月份/绿色包装箱数目/红色包装箱数目/橙色包装箱数目/蓝色包装箱数目。涵盖去年12月和今年前四个月,以空行分隔两年的数据 # cat inventory-shipped Jan 13 25 15 115 Feb
























分享
相关推荐





作者
发表评论
专题系列






0 条评论
评论者的用户名
评论时间暂时还没有评论.