
Unicode 字符集与 UTF-8 编码系统
Synopsis: Unicode 只是包含了所有语言符号、图形符号等的统一字符集(character set,每个字符都有唯一的 Unicode code point),但它并没有规定字符在计算机内部或网络中如何进行存储和传输,即它不是一个编码系统(encoding)。UTF-8 / UTF-16 / UTF-32 分别都实现了将 Unicode 字符编码成由 0 或 1 组成的字节序列,换言之,它们才是实现了 Unicode 规范的 encoding
1. 字符集的演变
1.1 美国的 ASCII
从根本上讲,计算机只处理由 0 或 1 表示的二进制比特位(bit)。每 8 bits 表示一个 字节(byte) ,共 2^8=256 种状态,从 0000 0000 到 1111 1111
计算机一开始由美国发明后,他们使用 1 个字节的后 7 bits 来表示 128 个字符: 包含英文字母的大小写、数字、各种标点符号和设置控制符,即 ASCII - American Standard Code for Information Interchange(美国信息交换标准代码)
| 字符 | 二进制 | 十进制 | 十六进制 |
|---|---|---|---|
| A | 0100 0001 |
65 | 0x41 |
| a | 0110 0001 |
97 | 0x61 |
用十进制的数值 65 来表示字母 M, 那么 65 就是 A 的 code point
1.2 GBK 等其它国家的字符集
后来全球越来越多的国家也都使用了计算机,为了在计算机中显示或存储各自国家的语言字符,他们又分别实现了多种字符集:
- Latin-1: 也称为 ISO 8859-1,将编码范围从 ASCII 的 0x00 - 0x7F 扩展到 0x00 - 0xFF 共能表示
2^8=256个字符(完全向下兼容 ASCII)。Latin-1收录的字符除 ASCII 字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。因为Latin-1的编码范围使用了单字节内的所有空间,在支持Latin-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,当读取一个未知编码的文本时,使用Latin-1编码永远不会产生解码错误。 使用Latin-1编码读取一个文件的时候也许不能产生完全正确的文本解码数据, 但是它也能从中提取出足够多的有用数据。同时,如果你之后将数据写回去,原先的数据还是会保留的 - GB2312: 是中华人民共和国国家标准简体中文字符集,共收录 6000 多个常用汉字,基本满足了汉字的计算机处理需要,但是它不能处理人名、古汉语等方面出现的罕用字和繁体字。对于 ASCII 中已有的 128 个字符还是用 1 个字节表示,其余汉字或符号用 2 个字节表示,关于 GB2312 如何兼容 ASCII 请 参考
- Big5: 繁体中文常用的字符集标准,共收录 13000 多个汉字
- GBK: Chinese Internal Code Extension Specification(汉字内码扩展规范),共收录 21000 多个汉字、800 多个图形符号,它完全向下兼容
GB2312。注意: GBK 与后续要讲的 UTF-8 完全不兼容,所以要注意使用相同的编码系统来 Encode / Decode,否则就会乱码! - GB18030:是中华人民共和国现时最新的
变长多字节字符集,共收录 70000 多个汉字
还有其它好多国家都制定了各自的字符集方案(安装 Notepad++,菜单 [编码] → [编码字符集]),比如韩语的 EUC-KR 字符集,日语的 Shift_JIS 和 EUC-JP 字符集,俄语 KOI8-R 字符集
微软使用 "Windows Code Pages" 来判断当前系统要使用的默认字符集,比如简体中文的 Code Page 是 CP936,繁体中文的 Code Page 是 CP950
查看当前系统的 Code Page:
Microsoft Windows [版本 10.0.14393] (c) 2016 Microsoft Corporation。保留所有权利。 C:\Users\wangy>chcp 活动代码页: 936
修改成 ASCII 字符集所对应的 Code Page 437(只在当前 CMD 命令行窗口中生效):
Windows 系统中特有的 ANSI 会根据你设置的系统 locale 来区分使用什么字符集:
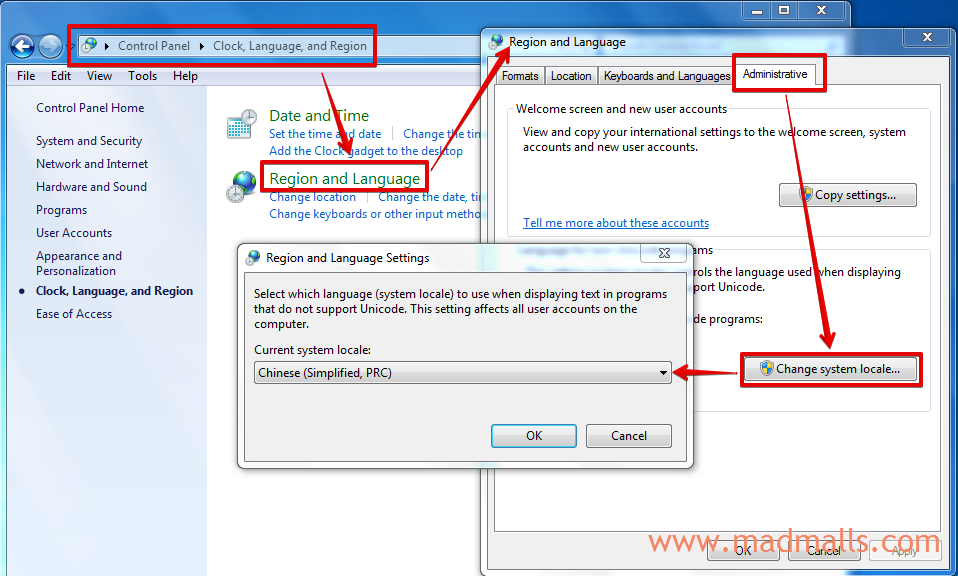
比如改成简体中文,那么 ANSI 实际是 GBK 字符集(Windows 95 之前 是 GB2312 字符集); 如果改成繁体中文,那么 ANSI 实际是 Big5 字符集; 如果改成韩文, 那么 ANSI 实际是 EUC-KR 字符集
Linux 也是靠 locale 来判断使用什么语言和字符集的:
1.3 全球统一的 Unicode 字符集
多个 字符集 会存在 编码规则 冲突的问题,可能会用同一个 code point 来表示两个不同的字符,或者对相同的字符使用不同的 code point 。随着互联网的发展,当数据在不同的计算机之间以不同的 编码规则 传输时,会增加数据损坏或错误(乱码)的风险
于是,Unicode, Universal Coded Character Set 标准出现了,它旨在为全世界每种语言、图形符号、emoji(❤️) 等每个字符都分配了唯一的 Unicode code point,计算机只要支持这一个字符集,就能显示所有的字符,再也不会有乱码了。它使用 4 个字节(32 bits),从 U+0000(表示 null)开始来表示每个字符的 Unicode code point,目前最新版本共收录了大约 15 万个字符,并且还在稳步扩展:
- 2003 年,Unicode 将它的可用 code points 空间限制为 21 bits,由
17(2^5) 个平面(planes)组成,每个平面有2^16=65536个 code points,也就是说 目前 Unicode 字符集能容纳的大小是2^21=2,097,152个 code points - 0 号平面也叫 Basic Multilingual Plane (BMP,基本多语言平面),包含几乎所有现代语言的最常用的字符,以及大量的符号,其 code points 的范围是
U+0000至U+FFFF。BMP中前 128 位跟 ASCII 一样,后面大多数 code points 分配给了中日韩统一表意文字 - Chinese, Japanese, Korean (CJK) unified ideograph - 1 - 16 号平面也叫 Supplementary Multilingual Plane (SMP,辅助平面),其 code points 的范围是
U+010000至U+10FFFF,那些不常用的汉字就属于这些平面中
强烈推荐 https://graphemica.com 这个网站,不仅可以查询各字符的 Unicode code point,还能显示该字符用 UTF-8 / UTF-16 / UTF-32 等编码后的值,不仅有字符的含义解释,甚至汉字还有普通话和粤语的拼音 😍
| 字符 | Unicode code point | 十进制 |
|---|---|---|
| A | U+0041 |
65 |
| 汉 | U+6C49 |
27721 |
| 𪸿 | U+2AE3F |
175679 |
2. 最流行的编码系统 UTF-8
每个字符的 Unicode code points 确定下来之后,计算机中要用多少个字节来表示呢?比如字符 A 是用 1 个字节还是 2 个字节,或者 4 个字节来表示?
UTF-32: 是固定长度编码,每个 Unicode code points 都使用 4 个字节(32 bits)来存储和传输UTF-16: 是可变长度编码,不同的 Unicode code points 可用 2 个字节(16 bits)或 2 个 2 字节(2 * 16 bits)来存储和传输UTF-8: 是可变长度编码,每个 Unicode code points 使用 1 至 4 个字节来存储和传输
2.1 UTF-32
用 4 个字节来表示每个字符,完全对应 Unicode code points:
| 字符 | Unicode code point | UTF-32 十六进制 | UTF-32 二进制 |
|---|---|---|---|
| A | U+0041 |
0x0000 0041 | 0000 0000 0000 0000 0000 0000 0100 0001 |
| 汉 | U+6C49 |
0x0000 6C49 | 0000 0000 0000 0000 0110 1100 0100 1001 |
UTF-32 的主要优点是可以直接索引 Unicode code points,在编码后的字节序列中找到第 N 个 code point 是恒定时间操作,时间复杂度为 O(1)。相反,可变长度代码需要顺序访问才能找到字节序列中的第 N 个 code point
UTF-32 的主要缺点是空间效率低(所以现在几乎不使用它),每个 code point 都使用 4 个字节,包括 11 位始终为 0(目前 Unicode 字符集的大小是 2^21)。在大多数文本中,超出 BMP 平面的字符相对较少,通常在估计大小时可以忽略。这使得按 UTF-32 编码后的文本大小差不多是按 UTF-16 编码后的大小的两倍,它最多可以是 UTF-8 大小的四倍,具体取决于此文本文件中占有多少比例的 ASCII 子集中的字符(UTF-8 使用 1 个字节来编码 ASCII 中的字符)
2.2 UTF-16
基本多语言平面(U+0000 至 U+FFFF)的字符用 2 个字节编码,辅助平面(U+010000 至 U+10FFFF)的字符用 2 个 2 字节编码:
| 字符 | Unicode code point | UTF-16 十六进制 | UTF-16 二进制 |
|---|---|---|---|
| A | U+0041 |
0x0041 | 0000 0000 0100 0001 |
| 汉 | U+6C49 |
0x6C49 | 0110 1100 0100 1001 |
| 𪸿 | U+2AE3F |
0xD86B 0xDE3F | 1101 1000 0110 1011 1101 1110 0011 1111 |
你会发现如果字符是在基本多语言平面中,直接按 Unicode code point 转换成对应的十六进制即可; 如果是辅助平面中的字符(比如 𪸿),那么要使用 2 个 16 bits 来编码
UTF-16 represents non-BMP characters (those from U+10000 through U+10FFFF) using a pair of 16-bit words, known as a surrogate pair.
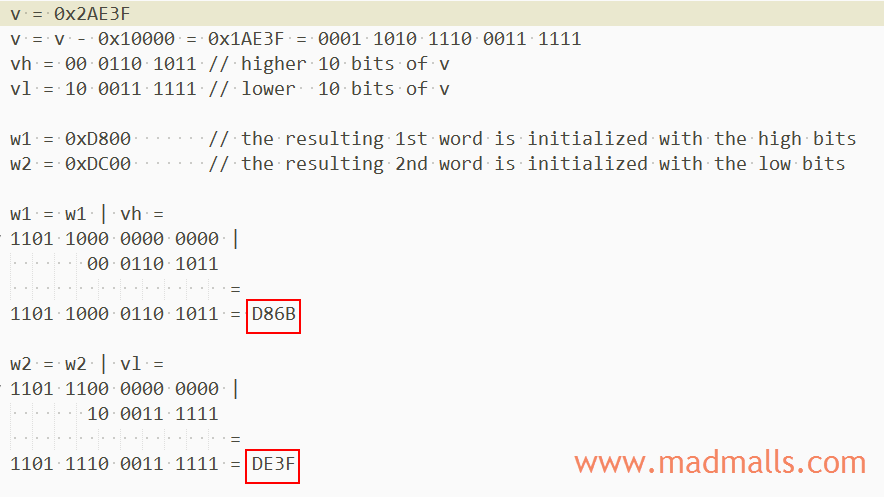
𪸿 的 UTF-16 编码计算过程如下图:
补充: Unicode 没有(永远也不会)将基本多语言平面内的
U+D800至U+DFFF分配给任何字符,因此,这个空段可以用来映射辅助平面的字符
首先将它的十六进制 0x2AE3F 减去辅助平面中的第一个 code point 值 0x10000 得到 0x1AE3F,转化成二进制后,分成前后两部分各 10 bits。分别再进行 或 运算,将前 10 bits 映射到 0xD800 – 0xDBFF 之间,将后 10 bits 映射到 0xDC00 - 0xDFFF,得到最终的 UTF-16 编码为 0xD86B 0xDE3F
那么在一串 UTF-16 编码的字节序列中,怎么确定其中 2 个字节是单独表示基本多语言平面中的一个字符,还是要与后面的另外 2 个字节组合成一起(共 4 个字节)来表示辅助平面中的一个字符呢?
答案是: 当遇到两个字节,且它的编码值在 U+D800 至 U+DBFF 之间时,那么可以断定紧跟在后面的两个字节的编码值肯定在 U+DC00 至 U+DFFF 之间,最终将这四个字节组合在一起解码为辅助平面中的一个字符
UCS-2 编码系统是什么?
1988 年成立的 Unicode 组织和 1989 年成立的 UCS 组织不约而同地都想实现一套 通用编码字符集(Universal Coded Character Set),只不过当时不像现在网络通讯这么发达,它们彼此都不知道对方的存在。1990 年 UCS 就公布了第一套编码系统 UCS-2,使用 2 个字节表示每个字符的 code point。因为当时收录的字符不多,2 字节足够了,也就是 0 号平面 BMP
此时,Unicode 组织才发现还有另外一个类似的组织在做这件事,于是双方沟通后很快就达成一致: 世界上不需要两套统一字符集。1991 年 10 月,两个团队决定合并字符集,到现在为止全球只有一套统一字符集 -- Unicode
UCS-2 是固定长度编码(2 字节),它只能编码 BMP 基本多语言平面上的字符,跟 UTF-16 不同哦(于 1996 年 7 月公布)
2.3 UTF-8
UTF-8 由 Ken Thompson 和 Rob Pike 共同发明(这两位大神也是 Go 语言之父):
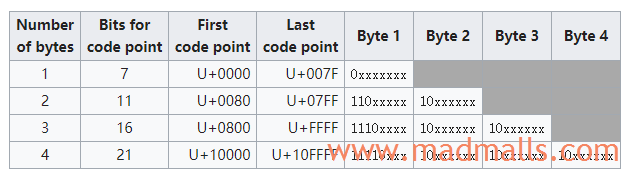
- 前 128 个字符(US-ASCII)只需要
1个字节 - 接下来的 1920 个字符需要
2个字节进行编码,涵盖了几乎所有拉丁字母字母表的其余部分,以及希腊语、阿拉伯语、叙利亚语等,以及组合变音符号标记 - 基本多语言平面 BMP 的其余字符需要
3个字节,包括大多数中日韩统一表意文字(CJK)中的常用字符 - 辅助平面 SMP 中的字符需要
4个字节,其中包括不太常见的 CJK 字符、各种数学符号和表情符号(emoji)🎉 - 每个字符按 UTF-8 编码后,由第 1 个字节的开头的
1的数目表示编码总共有多少个字节:0xxxxxxx表示只有 1 个字节(与 ASCII 兼容)、110xxxxx表示有 2 个字节、1110xxxx表示有 3 个字节、11110xxx表示有 4 个字节。多字节编码中,除了第 1 个字节外,后面都是10xxxxxx形式
Unicode code point 如何转换成 UTF-8 编码?
- 根据字符的 Unicode code point 找到上表中对应的区间,比如
汉的U+6C49在表中第三行的U+0800至U+FFFF之间,所以确定它要用 3 个字节来编码 - 将字符
汉的 Unicode code point 用二进制表示为0110 1100 0100 1001,从最后一个 bit 开始,依次从后向前填充到1110xxxx 10xxxxxx 10xxxxxx中的 x 位置(如果 x 还有剩余的话,统一补 0),得到11100110 10110001 10001001,转换成十六进制就是E6 B1 89,因此汉的 UTF-8 编码是0xE6 0xB1 0x89
| 字符 | Unicode code point | UTF-8 十六进制 | UTF-8 二进制 |
|---|---|---|---|
| A | U+0041 |
0x41 | 0100 0001 |
| 汉 | U+6C49 |
0xE6 0xB1 0x89 | 1110 0110 1011 0001 1000 1001 |
| 𪸿 | U+2AE3F |
0xF0 0xAA 0xB8 0xBF | 1111 0000 1010 1010 1011 1000 1011 1111 |
UTF-8 的优点:
- UTF-8 编码比较紧凑,完全兼容 ASCII
- 可以自动同步: 它可以通过向前回朔最多 3 个字节就能确定当前字符编码的开始字节的位置
- 是前缀编码: 当从左向右解码时不会有任何歧义也并不需要向前查看(像 GBK 之类的编码,如果不知道起点位置则可能会出现歧义)
- 没有任何字符的编码是其它字符编码的子串,或是其它编码序列的字串,因此搜索一个字符时只要搜索它的字节编码序列即可,不用担心前后的上下文会对搜索结果产生干扰
UTF-8 对所有常用的字符最多只需要用 3 个字节就能表示,编码效率高。自 2009 年以来,UTF-8 一直是万维网的主导编码,截至 2019 年 10 月,占据 94.1%
3. 编码实验
什么是
BOM(byte-order mark)?
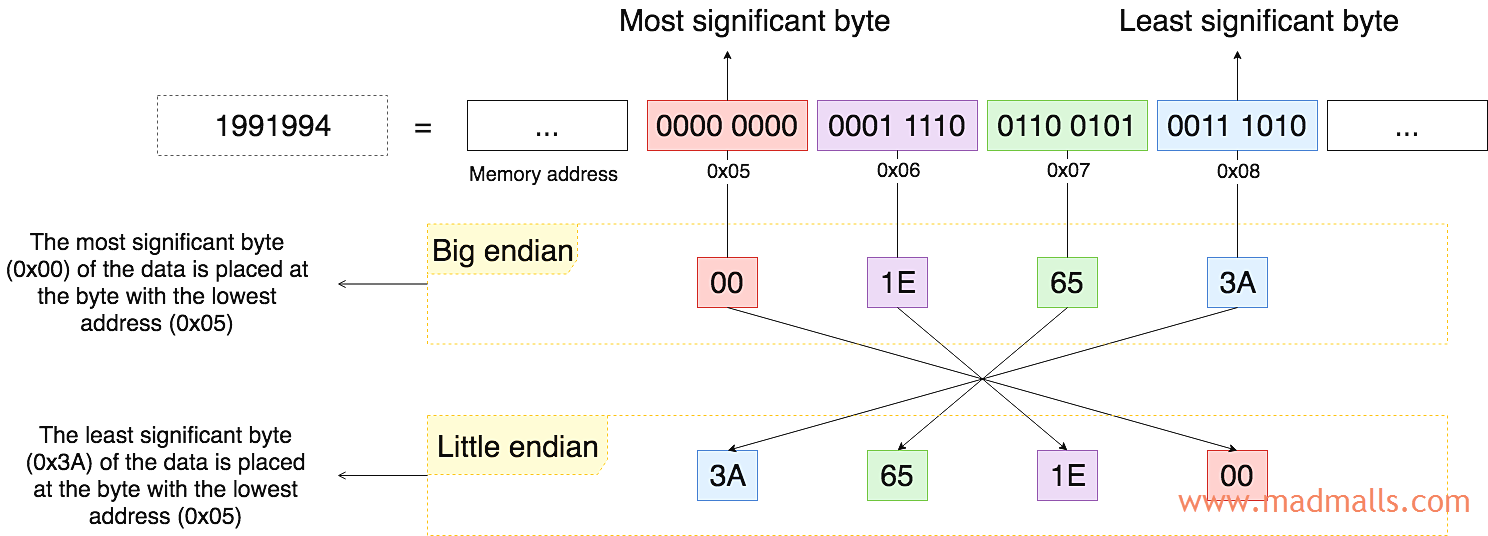
假设要在计算机中用 4 个字节来存储 1991994 这个整数,其二进制表示为 0000 0000 0001 1110 0110 0101 0011 1010,最右边的 bits 对二进制数的值影响最小,称为 最低有效字节(LSB,Least Significant Byte);相反,最左边的 bits 对二进制数的值影响最大,称为 最高有效字节(MSB,Most Significant Byte)。注意,上图中的内存地址从左至右依次增大,数据从低地址往高地址方向开始存:
大端序(BE,big endian): the MSB of the data is placed at the byte with the lowest address. 即先存高位字节那一端0x00 0x1E 0x65 0x3A,本文章节 2.1 和 2.2 中的表格中的十六进制表示都是基于大端序的哦。当然你也可以换成小端序来表示,在 https://graphemica.com 这个网站上也都可以查到!小端序(LE,little endian): the LSB of the data is placed at the byte with the lowest address. 即先存低位字节那一端0x3A 0x65 0x1E 0x00
PowerPC(比如 iOS)系列 CPU按大端序存,而 x86(比如 Windows)系列 CPU 按小端序存,如果它们只是在单机上存储或读取是没有问题的,但是如果通过网络互相通信了,其中一方必须在内部将字节序调整跟对方一样。TCP/IP 协议在 RFC1700 中规定网络字节序必须使用大端序!
而 Unicode 字符集的编码实现方案 UTF-32 / UTF-16,使用 BOM(byte-order mark) 来标记字节顺序,Unicode 规范建议可以在字节序列前添加 BOM 标记来表明后续的字节序是大端序还是小端序。由于 U+FEFF 没有分配给任何字符(zero width no-break space),所以我们可以使用 FE 和 FF 这两个字节的先后顺序来表示大端序或小端序:
| 编码系统 | 十六进制 BOM |
|---|---|
| UTF-32(big endian) | 00 00 FE FF |
| UTF-32(little endian) | FF FE 00 00 |
| UTF-16(big endian) | FE FF |
| UTF-16(little endian) | FF FE |
3.1 GBK
安装破解版的 UltraEdit,打开它时,默认采用操作系统的编码系统,比如我的 Windows 简体中文系统中 ANSI 其实是 GBK 编码(章节 1.2 有说明)
依次输入 A 和 汉,然后点击菜单 [Edit] → [Hex mode],显示这两个字符的 GBK 编码依次为 41 和 BA BA
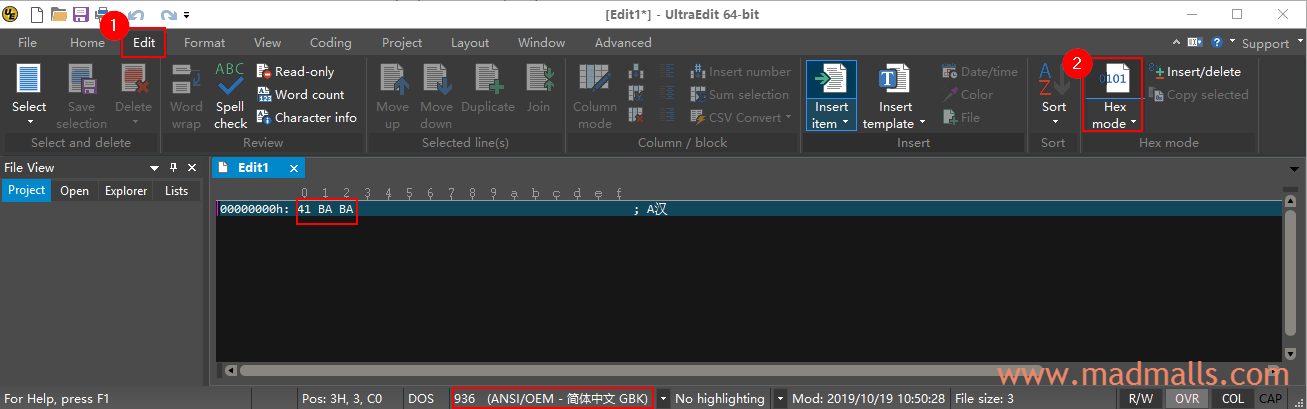
但是,当我复制粘贴 𪸿 这个 Unicode 字符进去时,会提示不支持此字符,因为 GBK 字符集中没有
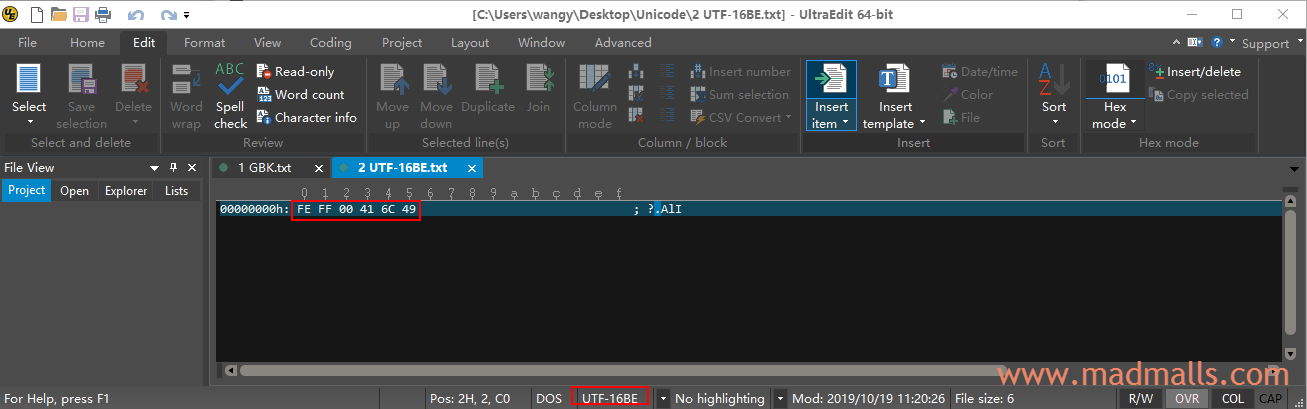
3.2 UTF-16BE
用 UltraEdit 新建一个文件,依次输入 A 和 汉 并保存时,弹出框中 [Encoding] 选择 [UTF-16 - big-endian (with BOM)]。查看它的编码的十六进制,前面的 FE FF 表示这是 UTF-16 的大端序,00 41 是 A 的 UTF-16BE 编码,6C 49 是 汉 的 UTF-16BE 编码:
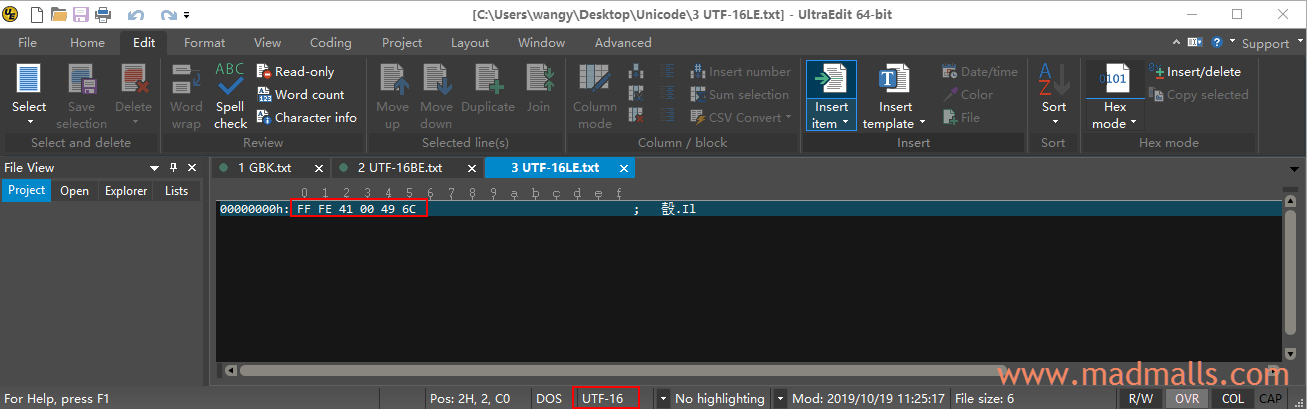
3.3 UTF-16LE
用 UltraEdit 新建一个文件,依次输入 A 和 汉 并保存时,弹出框中 [Encoding] 选择 [UTF-16 (with BOM)],当前 CPU 为 x86 系列,所以默认采用小端序。查看它的编码的十六进制,前面的 FF FE 表示这是 UTF-16 的小端序,41 00 是 A 的 UTF-16LE 编码,49 6C 是 汉 的 UTF-16LE 编码:
3.4 UTF-8
用 UltraEdit 新建一个文件,依次输入 A 和 汉,然后复制粘贴 𪸿 这个 Unicode 字符进去,保存时在弹出框中 [Encoding] 选择 [UTF-8 - no BOM)]。查看它的编码的十六进制,41 是 A 的 UTF-8 编码,E6 B1 89 是 汉 的 UTF-8 编码,F0 AA BB BF 是 𪸿 的 UTF-8 编码:
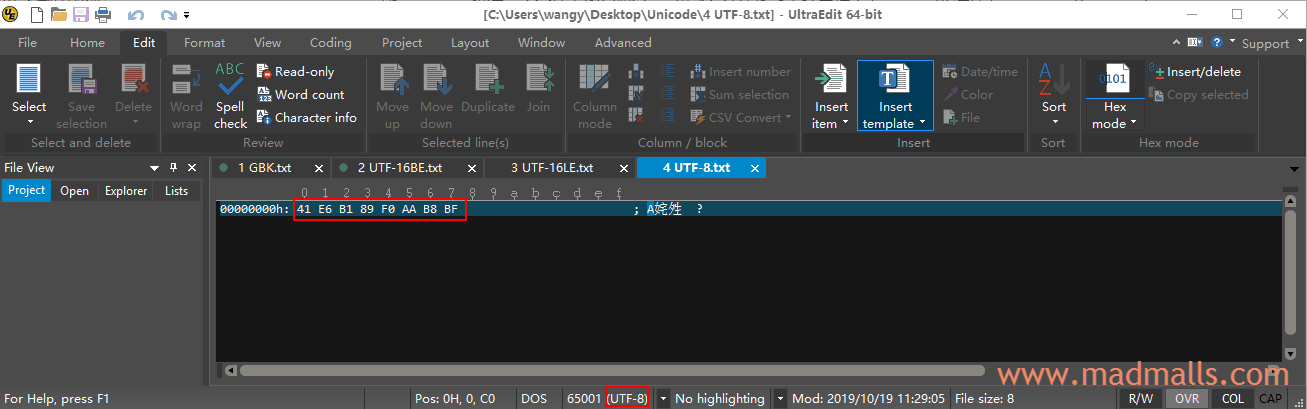
不知道为何保存后,UltraEdit 没有显示 𪸿 字符,而 "记事本"、"Notepad++"、"Sublime Text 3" 打开此文件后都能正常显示 𪸿 字符
如果保存时,选择 [UTF-8 (with BOM)] 的话,则会在前面添加 EF BB BF(它是 U+FEFF 的 UTF-8 编码值)。但是,比如你要写一个 shell 脚本,如果用 UTF-8 (with BOM) 的话,Bash 解析器无法解析此脚本:
[root@CentOS ~]# cat test.sh #!/bin/bash whoami [root@CentOS ~]# sh test.sh : No such file or directoryh test.sh: line 2: $'\r': command not found test.sh: line 3: $'whoami\r': command not found
从章节 2.3 的那张图可以看出,UTF-8 不需要 BOM,所以强烈建议采用 UTF-8 (without BOM) 编码方式
4. 如何避免乱码
计算机只认识 0 和 1,任何输入输出都是字节流,应用程序(包括操作系统)需要按照某一编码系统将字符图形数据,编码成字节流进行存储或传输。如果 编码(Encode) 和 解码(Decode) 两个步骤所使用的编码系统不一致,就会出现乱码。如果应用程序不支持文件所使用的编码系统,也是会乱码的
4.1 建议优先使用 UTF-8 without BOM
😥 如果你用 "Notepad++" 创建一个新的空文件,依次点击菜单 [编码] → [编码字符集] → [韩文] → [EUC-KR],然后复制粘贴 안녕,world 进去并保存为 0-EUC-KR.txt,然后:
- 用 "记事本" 打开,显示错误内容
救崇,world,因为 "记事本" 程序不支持EUC-KR字符集 - 用 "UltraEdit" 打开,因为 Windows 简体中文系统默认使用 GBK 编码,所以显示错误内容
救崇,world。但是,在编辑器下方状态栏中修改编码系统为 [EUC] → [51949 (EUC - 朝鲜语)] 后,正确显示안녕,world
😄 如果你用 "Notepad++" 创建一个新的空文件,依次点击菜单 [编码] → [使用 UTF-8 编码],然后复制粘贴 안녕,world 进去并保存为 0-UTF8-韩语.txt。然后,用 "记事本"、"Notepad++"、"Sublime Text 3" 打开此文件后都能正常显示 안녕,world 字符
所以,如果你创建新文件时,一直使用 UTF-8 编码系统的话,其它人基本上都能正确打开你的文件,因为 UTF-8 的支持太广泛了
4.2 下策是转换文件的编码系统
分别创建按 GBK 和 UTF-8 编码的两个文件 1-GBK.txt 和 2-UTF8.txt,内容都是 Hello,世界。然后用 "记事本"、"Notepad++"、"Sublime Text 3" 都能正常显示两个文件的内容,是因为编辑器程序都支持这两种编码系统,通过章节 3 的内容它们能够正确识别出文件是使用的哪种编码系统,从而用同一种方案 解码 即可
Windows 简体中文系统默认使用 ANSI/OEM - 简体中文 GBK,所以用 CMD 去查看 GBK 文件时,能够正常 解码 显示。但是,查看 UTF-8 文件时会乱码:
1. Windows 简体中文系统默认使用 GBK 编码系统 C:\Users\wangy\Desktop\Unicode>type 1-GBK.txt Hello,世界 C:\Users\wangy\Desktop\Unicode>type 2-UTF8.txt Hello锛屼笘鐣? 2. 通过 chcp 命令修改 code page 为代表 UTF-8 的 65001 后,正常解码显示 UTF-8 文件,而 GBK 文件会乱码 C:\Users\wangy\Desktop\Unicode>chcp 65001 Active code page: 65001 C:\Users\wangy\Desktop\Unicode>type 1-GBK.txt Hello������ C:\Users\wangy\Desktop\Unicode>type 2-UTF8.txt Hello,世界
同样的道理,由于 Linux 系统默认使用 UTF-8 编码系统,所以查看 GBK 文件时会乱码,而查看 UTF-8 文件时能够正常显示:
1. 默认正常显示 UTF-8 文件,而 GBK 文件会乱码 [root@CentOS ~]# locale LANG=en_US.UTF-8 LC_CTYPE="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_TIME="en_US.UTF-8" LC_COLLATE="en_US.UTF-8" LC_MONETARY="en_US.UTF-8" LC_MESSAGES="en_US.UTF-8" LC_PAPER="en_US.UTF-8" LC_NAME="en_US.UTF-8" LC_ADDRESS="en_US.UTF-8" LC_TELEPHONE="en_US.UTF-8" LC_MEASUREMENT="en_US.UTF-8" LC_IDENTIFICATION="en_US.UTF-8" LC_ALL= [root@CentOS ~]# cat 1-GBK.txt Hello£¬ˀ½ [root@CentOS ~]# cat 2-UTF8.txt Hello,世界 2. 用 iconv 工具将 GBK 编码的字节序列转换成 UTF-8 编码 临时转换并输出: [root@CentOS ~]# cat 1-GBK.txt | iconv -f GBK -t UTF-8 Hello,世界 或者保存到新文件中: [root@CentOS ~]# iconv -f GBK -t UTF-8 -o 3-conv-GBK-to-UTF8.txt 1-GBK.txt [root@CentOS ~]# cat 3-conv-GBK-to-UTF8.txt Hello,世界 3. 要想 vim 也能直接正常显示 1-GBK.txt 文件内容,需要在 ~/.vimrc 中添加如下行 " 字符编码 set encoding=utf-8 " 打开文件时,自动从下面的列表中选择正确的编码系统进行解码 [Decode] set fileencodings=utf-8,ucs-bom,cp936,gb18030,big5,euc-jp,euc-kr,latin1 set helplang=cn
GBK 文件名乱码问题请查看 中文文件名乱码











0 条评论
评论者的用户名
评论时间暂时还没有评论.