
Python 3 爬虫|第11章:爬取海量妹子图

Synopsis: 爬取 www.mzitu.com 全站图片,截至目前共 5162 个图集,16.5 万多张美女图片,使用 asyncio 和 aiohttp 实现的异步版本只需要不到 2 小时就能爬取完成。按日期创建图集目录,保存更合理。控制台只显示下载的进度条,详细信息保存在日志文件中。支持异常处理,不会终止爬虫程序。失败的请求,下次再执行爬虫程序时会自动下载
代码已上传到 https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎 star
1. 准备环境
1.1 安装 CentOS
建议使用 VMware 安装一台 CentOS-7.3 虚拟机,请参考: http://www.madmalls.com/blog/post/customize-centos-7-3-autoinstall-iso/
1.2 安装 Python3
请参考: http://www.madmalls.com/blog/post/deploy-flask-gunicorn-nginx-supervisor-on-centos7/#3-python3
1.3 安装 MongoDB
请参考: http://www.madmalls.com/blog/post/deploy-flask-gunicorn-nginx-supervisor-on-centos7/#4-mongodb ,如果是 Windows 请参考: http://www.madmalls.com/blog/post/win10-install-mongodb/
尝试使用
motor实现 MongoDB 异步操作,好像效率更差一些,所以放弃使用该模块。目前数据库操作是同步阻塞型,使用pymongo模块
1.4 安装 Git
代码已上传到 https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎 star,克隆代码:
[root@CentOS ~]# git clone https://github.com/wangy8961/python3-concurrency-pics-02.git [root@CentOS ~]# cd python3-concurrency-pics-02/
1.5 准备虚拟环境
如果你的操作系统是 Linux:
[root@CentOS python3-concurrency-pics-02]# python3 -m venv venv3 [root@CentOS python3-concurrency-pics-02]# source venv3/bin/activate
Windows激活虚拟环境的命令是:venv3\Scripts\activate
1.6 安装依赖包
如果你的操作系统是 Linux:
如果你的操作系统是 Windows(不会使用 uvloop):
2. 分析过程
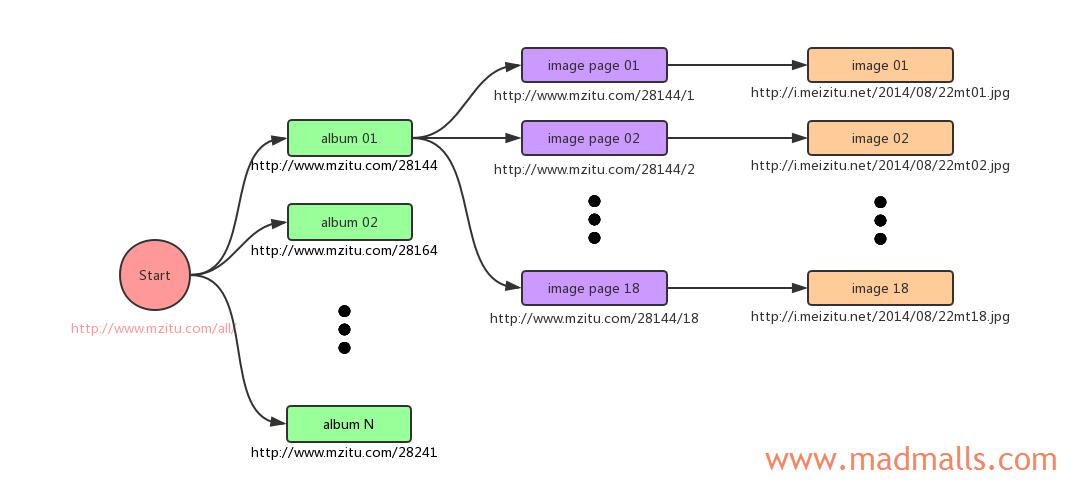
2.1 获取图集信息
使用 requests 模块或 aiohttp 模块来获取入口页面 http://www.mzitu.com/all/ 的 HTML 响应,然后通过 BeautifulSoup4 和 lxml 来解析 HTML 文档。每个 图集 按年份/月份被放在 <div class='all'></div> 下面的每个 <a href="图集URL">图集标题<a> 中。需要注意的是,早期图片需要访问 http://www.mzitu.com/old/ ,递归调用获取图集的函数即可
将获取的 5000 多个图集信息保存到 MongoDB 数据库的 albums 集合中
访问 http://www.mzitu.com/all/ 和 http://www.mzitu.com/old/ ,共
2 次请求





























15 条评论
评论者的用户名
评论时间小神龙
2018-12-27T01:55:53Z可以可以,老司机要开车了 嘿嘿
shaoze
2019-04-12T07:17:08Z说好的附件呢?
Madman shaoze Author
2019-04-12T07:18:40Z在 [分类] 的上方
yanwen
2019-07-28T14:29:44Z点阅读原文 跳转到妹子图去了??不能购买文章么??
Madman yanwen Author
2019-07-28T14:35:02Z登录后,如果你的余额够的话可以直接购买,否则需要先充值,谢谢
yanwen Madman
2019-07-28T14:47:33Z我源码改了一下。。购买了。。 余额是足够的。但是你的这个页面是有点问题。 那个阅读原文的红色按钮被 href 遮住了。点一下就跳转到 http://www.mzitu.com/all/ 具体怎么行程这个错误的 我也不知道。你要不注册个小号自己测试一下??
就这个文章有问题。其他文章没问题呢。
PS:博主写的文章不错。赞一个 哈哈哈。
Madman yanwen Author
2019-07-28T15:03:44Z是的,谢谢指出问题,已经修复了!
yanwen
2019-07-28T14:52:46Z哦。。对了。我使用的是firefox浏览器。不知道是不是跟这个有关。 也许跟chrome的css不一样???博主测试一下?
奶-维
2019-08-18T14:09:57Z你好,我想问下异步爬取的代码链接在哪,我好像没看到
Madman 奶-维 Author
2019-08-18T14:13:05Z文末的附件是完整代码,其中asynchronous.py就是
liuchaojk
2019-12-11T08:12:38Z还有个问题,人家有防爬虫技术,采回来的我看到好多图片是32X24的。。。。还是要改进下。
Foxgeek
2020-02-03T06:58:12Z大佬,2-分析中'思维导图'制作的软件是什么呀?
Madman Foxgeek Author
2020-02-04T08:08:31Z在线工具: https://www.processon.com/
Foxgeek Madman
2020-02-04T10:08:25Zthanks;大佬有时间多更新点课程呗,比如java-web系列的项目案例;现有的课程都相当给力!
alone
2020-12-17T09:22:59Zget_response方法里resp = requests.get(url, args, *kwargs)这行返回404了